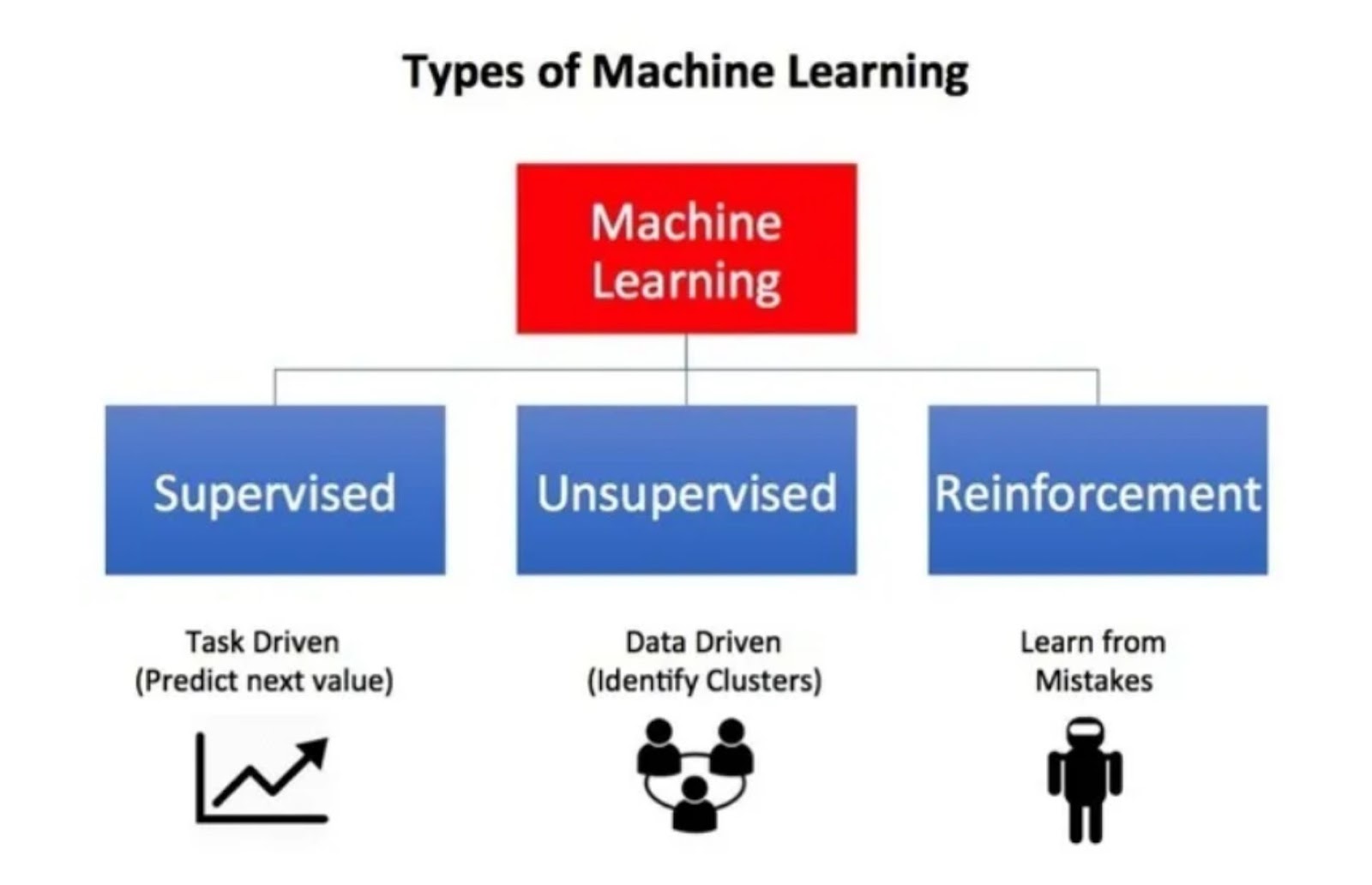
Welcome to this informative piece! If you’ve found yourself here, you’re likely well-versed in the growing significance of machine learning. The relevance of this field has surged impressively in recent years, fueled by the increasing demands in various business sectors and the rapid progress of technology. Machine learning is an extensive landscape with a plethora of algorithms that predominantly fall into three main categories:
- Supervised Learning: These algorithms aim to model the relationship between features (independent variables) and a target label, based on a set of observations. The resultant model is then employed to predict the label of fresh observations, using the defined features.
- Unsupervised Learning: These are algorithms that strive to uncover hidden patterns or intrinsic structures in unlabeled data.
- Reinforcement Learning: Operating on the principle of action and reward, these algorithms enable an agent to learn how to achieve a goal by iteratively determining the reward associated with its actions.
In this article, our focus will be on providing you with an overview of the commonly utilized reinforcement learning algorithms. Reinforcement Learning (RL) is undoubtedly one of the most thriving research domains in contemporary Artificial Intelligence, and its popularity shows no signs of diminishing. To equip you with a strong foundation in RL, let’s dive into five crucial elements you need to grasp as you embark on this exciting journey.
So, without further ado, let’s delve in.
(function($){ “use strict”; $(document).ready(function(){ function bsaProResize() { var sid = “32”; var object = $(“.bsaProContainer-” + sid); var imageThumb = $(“.bsaProContainer-” + sid + ” .bsaProItemInner__img”); var animateThumb = $(“.bsaProContainer-” + sid + ” .bsaProAnimateThumb”); var innerThumb = $(“.bsaProContainer-” + sid + ” .bsaProItemInner__thumb”); var parentWidth = “728”; var parentHeight = “90”; var objectWidth = object.parent().outerWidth(); if ( objectWidth 0 && objectWidth !== 100 && scale > 0 ) { animateThumb.height(parentHeight * scale); innerThumb.height(parentHeight * scale); imageThumb.height(parentHeight * scale); } else { animateThumb.height(parentHeight); innerThumb.height(parentHeight); imageThumb.height(parentHeight); } } else { animateThumb.height(parentHeight); innerThumb.height(parentHeight); imageThumb.height(parentHeight); } } bsaProResize(); $(window).resize(function(){ bsaProResize(); }); }); })(jQuery); (function ($) { “use strict”; var bsaProContainer = $(‘.bsaProContainer-32’); var number_show_ads = “0”; var number_hide_ads = “0”; if ( number_show_ads > 0 ) { setTimeout(function () { bsaProContainer.fadeIn(); }, number_show_ads * 1000); } if ( number_hide_ads > 0 ) { setTimeout(function () { bsaProContainer.fadeOut(); }, number_hide_ads * 1000); } })(jQuery);
Understanding Reinforcement Learning: How does it differ from other ML techniques?
- Reinforcement Learning (RL) is a subset of machine learning that empowers an agent to learn from an interactive environment through a process of trial and error, harnessing feedback from its own actions and experiences.
While supervised learning and RL both involve mapping between input and output, they diverge in terms of the feedback provided to the agent. In supervised learning, the agent receives the correct set of actions to perform a task as feedback. Conversely, RL uses a system of rewards and punishments as indicators for positive and negative behaviors.
When compared to unsupervised learning, RL differs primarily in its objectives. Unsupervised learning’s goal is to discover similarities and differences among data points. In contrast, the goal in RL is to develop a suitable action model that maximizes the agent’s total cumulative reward. The image below illustrates the action-reward feedback loop of a typical RL model.
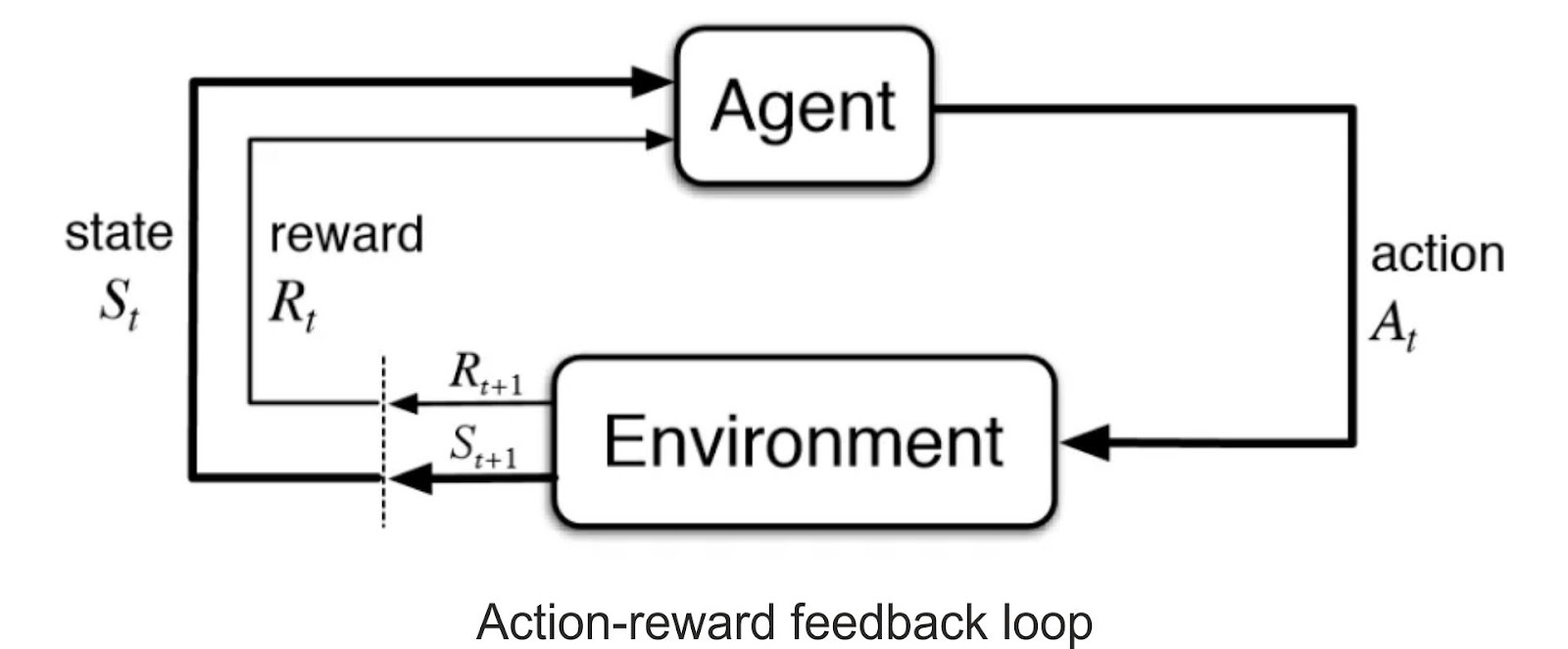
Formulating a Basic Reinforcement Learning Problem:
- Key Concepts and Steps A fundamental understanding of Reinforcement Learning (RL) involves grasping some crucial terms that outline the primary elements of an RL problem:
- Environment: The tangible world in which the agent operates.
- State: The agent’s current circumstance or position.
- Reward: Feedback the agent receives from the environment.
- Policy: The strategy that maps the agent’s state to its actions.
- Value: The prospective reward an agent would garner by performing an action in a particular state.
An engaging way to illustrate RL problems is through games. Let’s take the example of PacMan.

Here, the agent (PacMan) aims to consume food in the grid while eluding ghosts. In this scenario, the grid world represents the interactive environment where the agent acts. The agent gains a reward for eating food and receives a penalty if it gets killed by a ghost (resulting in a loss of the game). The states in this case are the locations of the agent within the grid world, and the agent winning the game represents the total cumulative reward.
When building an optimal policy, the agent confronts a predicament between exploring new states and simultaneously maximizing its overall reward. This is known as the Exploration vs Exploitation trade-off. The agent might need to make short-term sacrifices to achieve a balance and thus collect enough data to make the most beneficial overall decision in the future.
Markov Decision Processes (MDPs) offer a mathematical framework to describe an environment in RL, and almost all RL problems can be formulated using MDPs. An MDP includes a set of finite environment states (S), a set of possible actions (A(s)) in each state, a real-valued reward function (R(s)), and a transition model (P(s’, s | a)). However, real-world environments often lack any prior knowledge about the dynamics of the environment. In such instances, model-free RL methods prove beneficial.
One such commonly used model-free approach is Q-learning, which could be employed to create a self-playing PacMan agent. The concept central to Q-learning is the updating of Q values, which represent the value of performing action ‘a’ in state ‘s’. The subsequent value update rule forms the crux of the Q-learning algorithm.
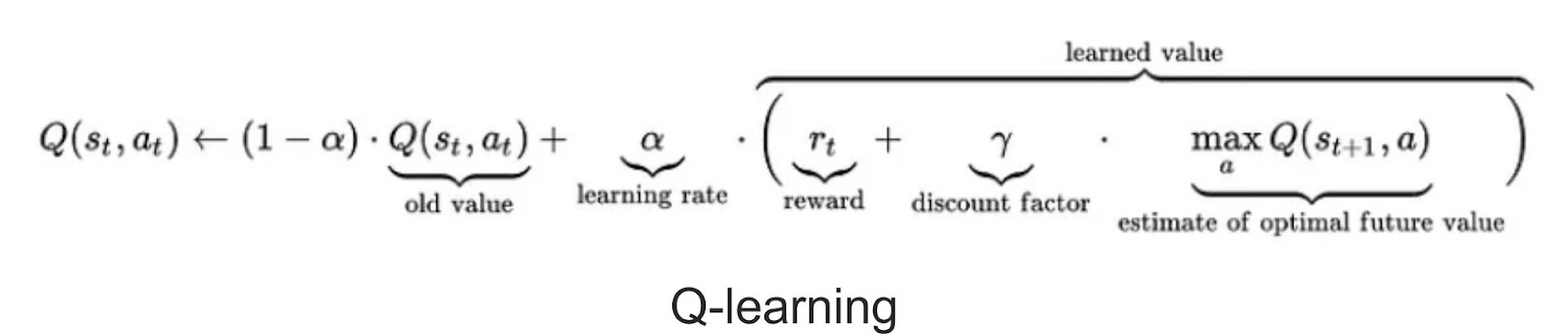
Popular Reinforcement Learning Algorithms:
- An Overview Two model-free RL algorithms often utilized in the field are Q-learning and SARSA (State-Action-Reward-State-Action). These algorithms differ mainly in their exploration strategies, while their exploitation strategies remain fairly similar. Q-learning is an off-policy method in which the agent learns value based on an optimal action ‘a*’ derived from another policy. On the other hand, SARSA is an on-policy method that learns value based on the current action ‘a’ extracted from its current policy. While these methods are straightforward to implement, they lack generality as they can’t estimate values for unobserved states.
This limitation is addressed by more advanced algorithms like Deep Q-Networks (DQNs). DQNs employ Neural Networks to estimate Q-values, thereby enabling value estimates for unseen states. However, DQNs are only capable of handling discrete, low-dimensional action spaces.
To tackle challenges in high-dimensional, continuous action spaces, Deep Deterministic Policy Gradient (DDPG) was developed. DDPG is a model-free, off-policy, actor-critic algorithm that learns policies effectively in such complex scenarios. The image below presents a representation of the actor-critic architecture, which forms the foundation of the DDPG algorithm.
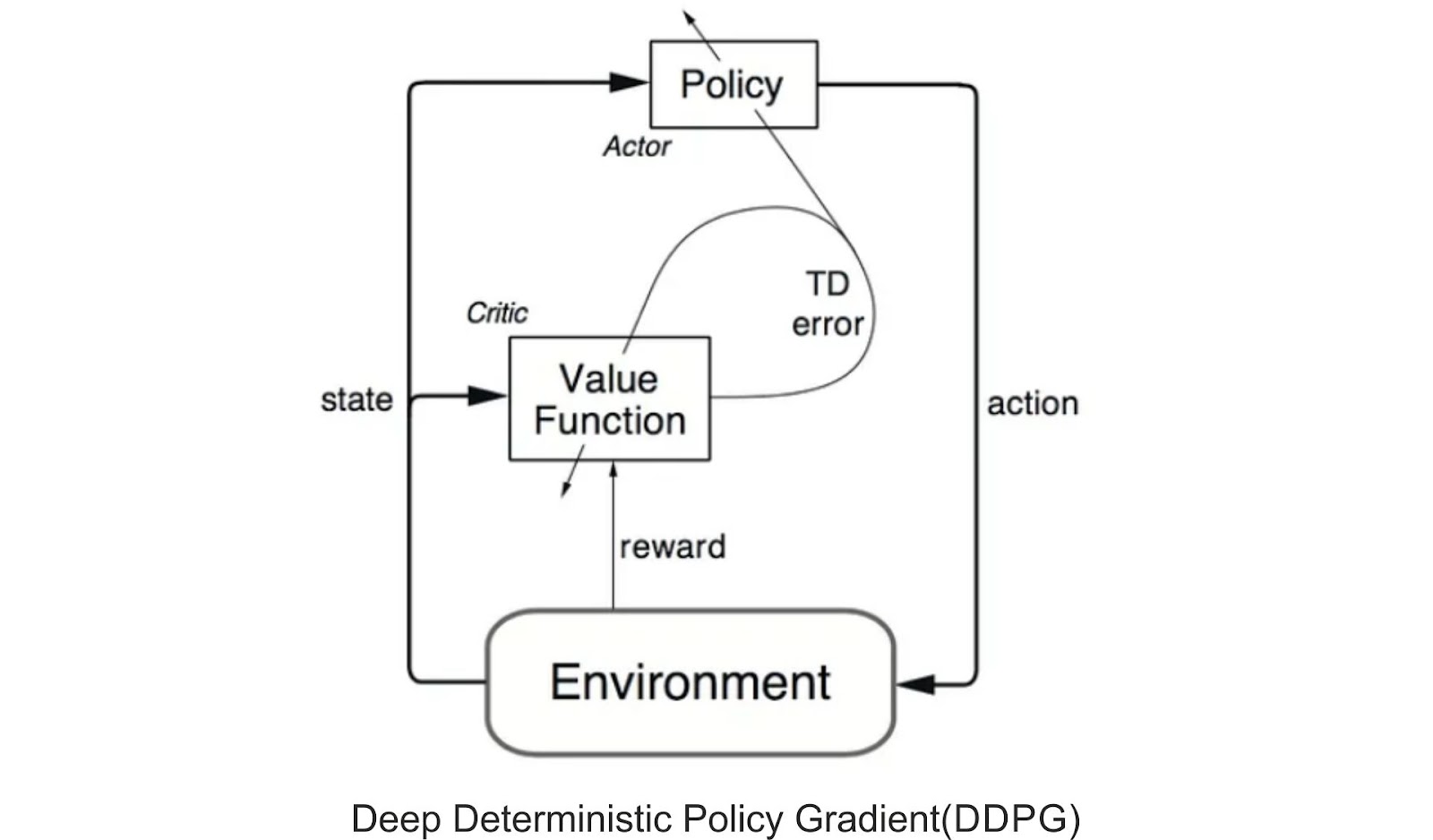
The Practical Applications of Reinforcement Learning:
- A Wide Spectrum Given that Reinforcement Learning (RL) relies heavily on substantial amounts of data, it finds its most effective use in domains where simulated data is readily accessible, such as in gameplay and robotics.
One of the most prominent uses of RL is in developing artificial intelligence for computer games. AlphaGo Zero stands as a shining example, being the first computer program to defeat a world champion in the ancient Chinese game of Go. Other instances include the creation of AI for ATARI games, Backgammon, and more.
In the field of robotics and industrial automation, RL is employed to equip robots with an efficient, adaptive control system that learns from their own experiences and behavior. A noteworthy example is DeepMind’s research on Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates. Here’s an interesting demonstration video of the same.
Beyond games and robotics, RL has found applications in numerous other areas. It powers abstractive text summarization engines and dialog agents (text, speech) that learn from user interactions and evolve over time. In healthcare, RL aids in discovering optimal treatment policies. The finance sector also leverages RL, deploying RL-based agents for online stock trading. These wide-ranging applications underscore the potential and versatility of RL in practical scenarios.
(function($){ “use strict”; $(document).ready(function(){ function bsaProResize() { var sid = “33”; var object = $(“.bsaProContainer-” + sid); var imageThumb = $(“.bsaProContainer-” + sid + ” .bsaProItemInner__img”); var animateThumb = $(“.bsaProContainer-” + sid + ” .bsaProAnimateThumb”); var innerThumb = $(“.bsaProContainer-” + sid + ” .bsaProItemInner__thumb”); var parentWidth = “728”; var parentHeight = “90”; var objectWidth = object.parent().outerWidth(); if ( objectWidth 0 && objectWidth !== 100 && scale > 0 ) { animateThumb.height(parentHeight * scale); innerThumb.height(parentHeight * scale); imageThumb.height(parentHeight * scale); } else { animateThumb.height(parentHeight); innerThumb.height(parentHeight); imageThumb.height(parentHeight); } } else { animateThumb.height(parentHeight); innerThumb.height(parentHeight); imageThumb.height(parentHeight); } } bsaProResize(); $(window).resize(function(){ bsaProResize(); }); }); })(jQuery); (function ($) { “use strict”; var bsaProContainer = $(‘.bsaProContainer-33’); var number_show_ads = “0”; var number_hide_ads = “0”; if ( number_show_ads > 0 ) { setTimeout(function () { bsaProContainer.fadeIn(); }, number_show_ads * 1000); } if ( number_hide_ads > 0 ) { setTimeout(function () { bsaProContainer.fadeOut(); }, number_hide_ads * 1000); } })(jQuery);
Reinforcement Learning – A Vital Building Block in AI’s Future
As we reach the end of this essential guide to Reinforcement Learning (RL), we hope you have gained valuable insights into the fascinating world of RL and its broad-ranging applications. From gaming to healthcare, RL is proving to be a transformative force in multiple industries.
At its heart, RL is about learning from experience. It encapsulates the timeless principle of trial and error, demonstrating how learning from our actions and their consequences can lead to optimized outcomes. It’s this very essence that allows RL algorithms to interact dynamically with their environment and learn how to maximize their reward.
The RL journey involves learning the basics of the RL problem, understanding how to formulate it, and then moving on to explore various algorithms such as Q-learning, SARSA, DQNs, and DDPG. Each of these algorithms brings unique elements to the table, making them suitable for different situations and requirements.
While RL is currently being used in various domains, it’s just the tip of the iceberg. Its potential is immense, and the future of AI will undoubtedly witness a greater influence of RL in shaping our world. As AI continues to evolve, mastering the basics of RL will equip you with a vital skillset to navigate and contribute to this rapidly advancing field.
In conclusion, Reinforcement Learning is not merely another machine learning technique, but rather a key that opens up new realms of possibilities in artificial intelligence. By continually improving its strategies based on feedback, RL serves as a driving force in AI’s quest towards mimicry and perhaps even surpassing human learning efficiency. As we forge ahead into the future, the importance of understanding and applying RL principles will only amplify. So, keep exploring, keep learning, and remember – the future belongs to those who learn.
The post Mastering the Basics: An Essential Guide to Reinforcement Learning appeared first on Datafloq.
