Article summary:
- The pharma sector has access to a lot of data: electronic health records, genomic information, real-world evidence, and more. All this data combined can be referred to as big data.Tapping into the patterns hidden in the big data can drive immense value for the sector.
- By turning to big data, the pharma sector can drive improvements at each step of the drug development process, starting from drug discovery and identifying new targets though clinical trials and regulatory approval to marketing and post-launch monitoring.
- Adopting big data in pharma is a challenging enterprise that will require companies to overcome organizational silos, seamlessly integrate disparate data sources, and ensure regulatory compliance.
Three years ago, the pharma sector faced an unprecedented challenge. Now the lessons learned in the crisis are fueling industry-wide change.
The commotion started a short time after the novel coronavirus made quick advancements around the world. Pharma companies drew the global spotlight striving to develop new vaccines for COVID-19 while continuing the supply of vital medical products to patients in need.
The sector withstood the crisis remarkably well. What came into sight though is that pharma companies can no longer afford reactive crisis management. New paradigms should emerge that can help the industry battle long-overdue issues, namely:
- The cost of developing a new drug reaching $2,284 million in 2022
- Average cycle times increasing to 7.09 years in 2022
- The return on investments in pharma R&D falling down to 1.2%.
Industry players may lock scientific partnerships, invest in emerging markets, and diversify their product portfolios to battle those issues. However, technology enthusiasts with a decade of experience delivering big data consulting services and pharma software solutions, we suggest considering another way – one based on data.
In this blog post, we look into the potential of big data in pharma and explore essential ways in which the big data technology changes the way drugs are developed, approved, and marketed.
What is big data in pharma, and how does it translate into value?
The pharma sector generates immense amounts of information. Clinical trial data, electronic health records, genomics information, real-world evidence, and patient-reported outcomes – all these data entries combined can be referred to as big data.
Essentially, big data is voluminous and diverse information of any format and from any source that can be converted into insights via analytics.
Here’s what the standard process of translating big data into big insights looks like:
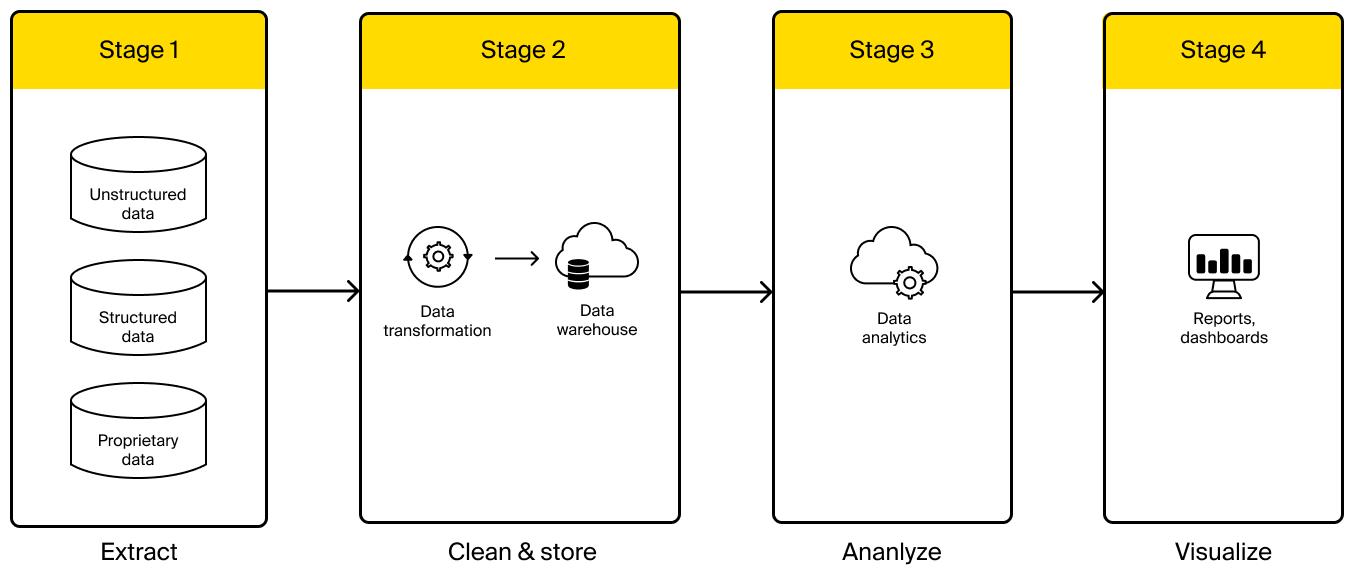
It all starts with collecting relevant data. The types and sources of it may vary a lot. The common types of information making up big data in pharma span:
- Clinical trial data that encompasses information collected during the evaluation of drugs. It may include study protocols, participant demographics, medical history, treatment responses, adverse events, lab test results, and more.
- Real-world evidence that includes data collected outside of controlled clinical trial settings in real clinical practice. It could span claims, data from wearables and electronic health records, as well as patient-reported outcomes.
- Genomics and molecular data that involves individual genetic information, including DNA variations, gene expression profiles, and genomic biomarkers, as well as information about the structure, interactions, and functions of molecules relevant to drug discovery.
- Electronic health records that include a patient’s medical history, allergies, diagnoses, lab results, and other relevant information.
- Imaging data that spans X-rays, MRIs, and CT scans.
- Pharmacovigilance and adverse event reports that shed light on adverse events and safety concerns associated with drugs.
- Scientific literature that spans research papers, conference proceedings, and patents.
- “Omics data” that refers to large-scale datasets generated from so-called “omics” disciplines, such as genomics, metabolomics, proteomics, transcriptomics, and others.
Before being loaded into a data warehouse (think: centralized storage for all pharmaceutical big data), the information retrieved from multiple sources undergoes cleaning and transformation. This is an important step that ensures the data is clear, correct, and converted to unified formatting. The cleaned and groomed data is then stored in the data warehouse, where it is easily accessible for analytics.
The essential use cases of big data in the pharma industry
Drug development is a long and risky road. Very few drug candidates make it to the market. Out of 5,000 compounds that enter pre-clinical testing, only five, on average, make it to human testing. And only one out of the initial 5,000 gets approved for clinical use.
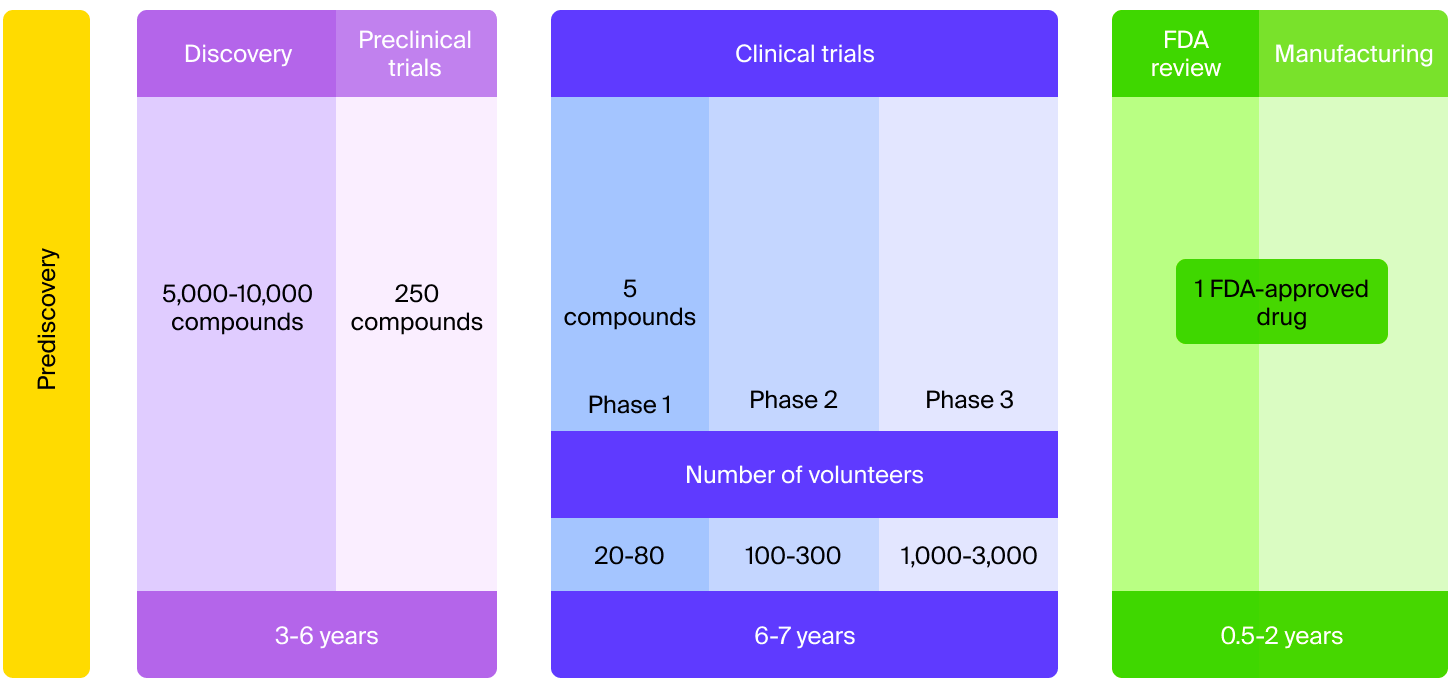
The good news is that at every step of the drug development process, pharmaceutical big data can come in handy.
Drug discovery
The foundational stage in pharmaceutical R&D, drug discovery starts with researchers understanding the process behind a disease at a cellular or molecular level. With potential targets identified, the process follows by searching for compounds that can interact with the target and interfere with its activity.
The key challenges that researchers face at this stage include identifying effective and safe targets, as well as finding compounds that have the desired potency, selectivity, and safety profiles.
By turning to pharmaceutical big data, researchers can resolve these issues and improve the speed and effectiveness of drug discovery.
Target identification and validation
Data sets from diverse sources can be integrated using big data. By analyzing these multidimensional data sets, researchers can identify new targets, drug indications, and drug response biomarkers faster and with fewer risks.
Many reference pharmaceutical big data sets for preclinical drug discovery have recently been created and made public:
- dbSNP: Single nucleotide polymorphisms (SNPs) for a wide range of organisms, including more than 150 million human reference SNPs.
- dbVar: Genomic structural variations generated mostly by published studies of various organisms, including more than 2.1 million human CNVs.
- COSMIC: Primarily somatic mutations from expert curation and genomewide screening, including more than 3.5 million coding mutations.
- 1000 Genomes Project: Genomes of a large number of people that provide a comprehensive resource on human genetic variation; this data set spans more than 2,500 samples.
- TCGA: Genomics and functional genomics data repository for more than 30 cancers across 10,000 samples. Primary data types include mutation, copy number, mRNA, and protein expression.
- GEO: Functional genomics data repository hosted by NCBI, including more than 1.6 million samples.
- ArrayExpress: Functional genomics data repository hosted by EBI, including more than 1.8 million samples.
- GTEx: Transcriptomic profiles of normal tissues, including more than 7,000 samples across 45 tissue types.
- CCLE: Genetic and pharmacologic characterization of more than 1,000 cancer cell lines.
These pharmaceutical big data sets are being extensively used to identify target molecules.
For example, in drug discovery, gene expression is one of the most widely used molecular features that has been used to inform target selection.
A group of researchers turned to one of the publicly available pharmaceutical big data sets to examine mRNA expression of the featured 844 breast cancer samples and compare those to normal breast tissues. As a result of analyzing big data included in the data set, they found out that the MTBP gene was significantly elevated in cancerous samples. Cross-referencing the findings with survival data also revealed that increased MTBP is significantly linked with poor patient survival.
In the example above, the target was proposed by the researchers. With big data in the pharmaceutical industry, targets can also be directly discovered by analyzing public big data. This way, a group of researchers sought druggable kinases that are oncogenic in breast cancer with no specific targets in mind. They analyzed gene expression data from public pharmaceutical big data sets and gene expression profiles of breast tumor-initiating cells to find 13 kinases with higher mRNA expression in cancer cell lines. Subsequent validation reduced the list of candidates to eight kinases, three of which were chosen as therapeutic targets.
Predictive modeling
Traditionally, researchers used plant or animal compounds to test candidate drugs. In September 2022, the US Senate passed the FDA Modernization Act 2.0, which allowed the use of alternatives to animal testing, including computer models.
The approach based on computer models allows for bypassing the inaccuracies and ethical issues associated with animal testing. It also has the potential to get the sector closer to a real representation of human biological activity.
One of the predictive modeling techniques used in pharma is pharmacokinetic modeling. Think: using pharmaceutical big data, mathematical equations, and computer simulations to understand how drugs “behave” in a human body. The method helps predict what happens to a drug once taken, including how it’s absorbed, distributed, metabolized, and eliminated.
Another promising technique that builds on big data in pharma is organ-on-chip technology. Organs on chips are polymer chips that use microfluidic cell structures to mimic human organ functionality and the physiological environment for in vitro disease modeling, drug testing, and precision medicine. We at ITRex have helped create an organ-on-a-chip platform that showed its effectiveness in addressing the issues associated with animal testing. Adopted by over 100 labs, the platform helped accelerate drug development and reduce costs associated with it.
Precision medicine
Precision medicine can be defined as an approach aiming to provide the right treatment to the right person at the right time. Traditionally, precision strategies remained mostly aspirational for most clinical problems. Today, the increasing use of big data in pharma holds a promise of reaching that aspirational goal.
Less dependent on prior knowledge, big data-based drug development has the potential to reveal unexpected pathways relevant to a disease, paving the way to a higher degree of precision and personalization. Some institutions are already leveraging the novel approach.
For instance, patients with a similar cancer subtype often respond differently when they receive the same chemotherapeutics. Drug responses are believed to be influenced by genomic instability. Using big data is becoming a popular way to study the complex relationship between genomics and chemotherapeutic resistance, toxicity, and sensitivity.
For instance, scientists can discover new cancer aberrations through the Pan-Cancer project, launched by the Cancer Genome Atlas research network. Several other projects, such as the Cancer Cell Line Encyclopedia and the Genomics of Drug Sensitivity in Cancer, are also generating pharmaceutical big data that investigate links between genomic biomarkers and drug sensitivity.
Clinical trials
The goal of a clinical trial is to tell whether a treatment is safe and effective for humans.
Usually, it follows in three sequential stages, starting from phase I, wherein a drug is tested on a small group of healthy individuals, through phase II, where the drug is tested on a larger group of people showing a specific condition being targeted, all the way to phase III that involves a larger number of patients.
The process has always been long and tedious. Luckily, with the wider adoption of big data in pharma, clinical trials are changing, too.
Faster recruiting
Nine out of ten trials worldwide can’t recruit enough people within their target timeframes. Some trials – especially those testing treatments for rare or life-threatening diseases – struggle to recruit enough people altogether. Typically, clinical trials involve two groups: a test group that gets a new treatment being tested and a control group that receives no treatment, a placebo, or the current standard of treatment.
Keeping in mind that patients with life-threatening conditions need quick help, they don’t want to be randomized to a control group. Add the need to recruit patients with relatively rare conditions, and the recruiting time stretches out for months.
Big data can help bypass the need for hiring a control group altogether. The idea is to use “virtual control groups” created based on pharmaceutical big data generated in past trials.
To find possible control group candidates, researchers use the key eligibility criteria from an investigational trial, for example, the key features of the disease and how advanced it is. A standard clinical trial selects control patients in a similar manner. The difference is that rather than relying on data collected during the current trial, past data is used. For now, though, a virtual control group is no replacement for a traditional clinical trial, but rather a quick way of evaluating if a new treatment is worth pursuing.
Another aspect of big data in pharma clinical trials is allowing for targeted recruiting. With novel techs, researchers can enroll patients based on new sources of data, say, social media. It becomes easier to weigh such criteria as genetic information, disease status, and individual characteristics.
Efficient trial management
Using big data in pharma can change the way clinical trials are designed and managed. Now researchers can track and detect drug exposure levels, the immunity provided by the medicine, the tolerability and safety of the treatment, and other factors that are crucial for recruits’ safety in real time, not just after the trials are completed.
The gains researchers achieve by turning to pharmaceutical big data span:
- Optimal sample size calculation: analyzing historical trial data can help inform sample size calculations.
- Stratification and subgroup analysis: big data can help identify patient characteristics, biomarkers, or genetic factors that influence treatment responses. This can help researchers stratify patients into subgroups to analyze treatment effects within specific populations.
- Adaptive trial design: analyzing pharmaceutical big data can facilitate adaptive trial design and let researchers change trial parameters based on interim results. Researchers can now dig into trends, treatment responses, or safety signals in order to make informed decisions about modifying trial parameters, such as sample sizes or enrollment criteria.
Quality control and compliance
Big data in pharma is revolutionizing traditional approaches to pharmaceutical quality control, enabling pharmaceutical companies to implement better quality control processes, streamline compliance efforts, and deliver safer and more effective medicines. The areas where pharmaceutical big data can drive significant impact include:
#Improved pharmacovigilance and adverse effect monitoring
Many adverse effects, especially rare ones, stay undetected due to a limited number of sampled individuals in clinical trials. That is why it is necessary to monitor drugs even after their release.
Considering that social media has become the platform for voicing customers’ concerns and reporting side effects, pharma companies started leveraging big data tools to harness this invaluable information.
Patient-reported adverse drug reactions gleaned from social media can even prove more accurate than those recorded by medical professionals. A study held by the FDA and Epidemico examined 6.9 million tweets and found 4,401 of them resemble an adverse event report. Further comparing the findings with the data held by the FDA revealed a high relation between informal social media reports and those documented in clinical trials.
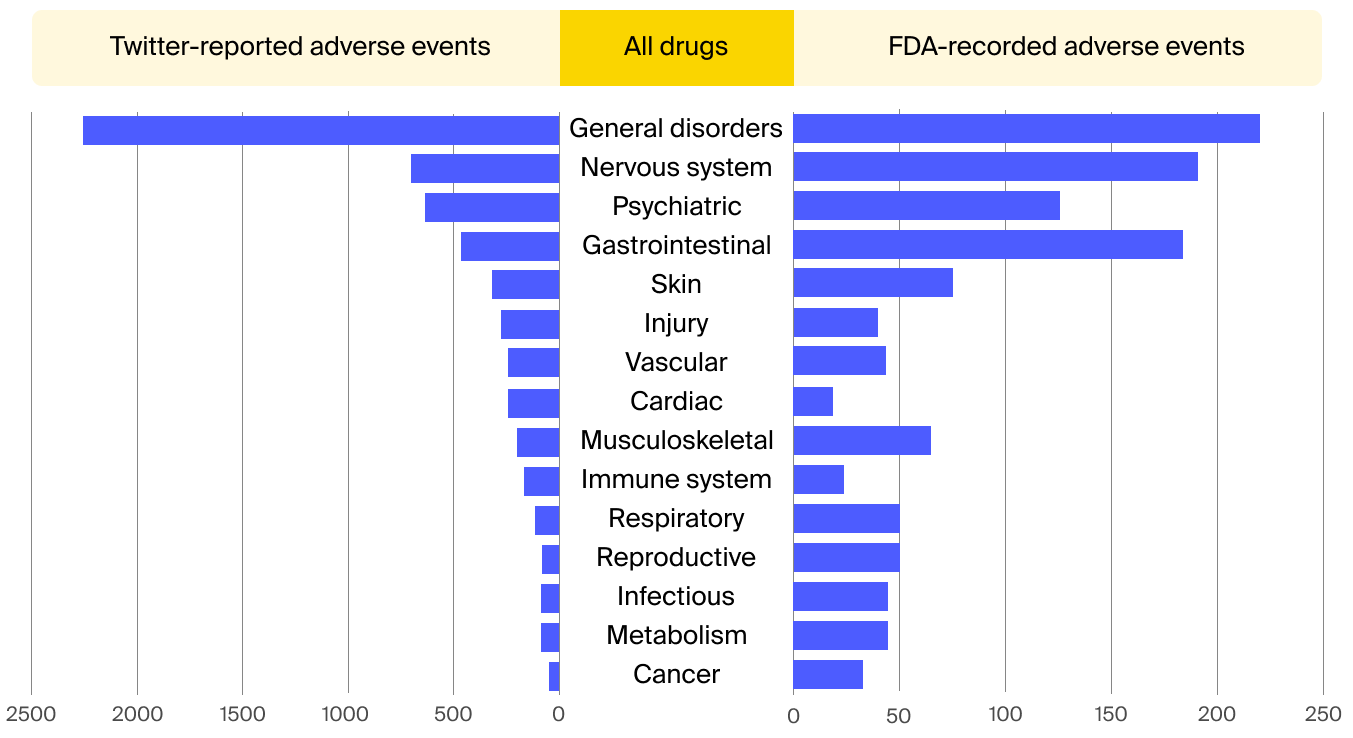
Enhanced compliance management
Big data in pharma plays an important role in facilitating regulatory compliance. Companies in the pharmaceutical industry are subject to a complex web of regulations, including GMP (Good Manufacturing Practices) and GCP (Good Clinical Practices), as well as strict data privacy laws. Big data in pharmaceuticals can help companies monitor key performance indicators, identify compliance gaps, and address potential issues in a proactive manner.
Pharma companies can minimize regulatory risks by detecting anomalies, deviations, and non-compliant activities early on by using automated monitoring systems and big data analytics solutions. Moreover, by combining historical data, machine learning algorithms, and advanced statistical techniques, pharmaceutical companies can develop predictive models that anticipate potential quality risks, optimize preventive maintenance schedules, and facilitate data-driven decision-making.
Sales and marketing
By using pharmaceutical big data, companies can predict industry trends and anticipate the sales of specific medicine based on demographic factors. This can help tailor pharma marketing campaigns to customer behavior.
Similarly to the use case described above, scraping through data available on the internet, including social media data, could help pharma companies gauge customer sentiment around their products. This may help pharma companies understand how their products are being received.
The challenges of adopting big data in pharma
Despite the benefits big data is driving in the pharma industry, companies are still conscious about overhauling their data management processes. We’ve put together a list of challenges that companies may face adopting big data in pharma to make your implementation process a less risky one.
Challenge 1. Integrating data sources
Having all data sources well linked is one of the key challenges for the pharma sector to overcome to reap the benefits of big data. Effectively using big data in the pharmaceutical sector requires integrating data generated at all stages of the drug development process, from discovery to regulatory approval to real-world application.
End-to-end data integration requires many capabilities: from collecting trusted data, connecting these sources, carrying out robust quality assurance, managing workflows, and more.
In general, we recommend avoiding overhauling your data infrastructures all at once due to the risks and costs involved. A safer approach is to integrate your data sources step by step, identifying the specific data types that need to be handled first and creating additional warehousing capabilities as needed. The goal is to tackle critical data first to get ROI as soon as possible. In parallel, you can develop scenarios for integrating data sources of a lower priority.
Challenge 2. Overcoming organizational silos
End-to-end data integration is barely possible without overcoming silos within an organization. Traditionally in pharma, different teams had responsibility for their systems and data. Shifting to a data-centric approach with a clear owner for each type of data across functional silos and through the data pipeline will facilitate the ability to generate value from big data in pharma.
Challenge 3. Regulatory compliance
Adopting big data in pharma and rolling out centralized data management systems, you must make sure the data is handled safely and securely. The FDA requires software used in the sector (e.g., systems used to handle electronic health records or manage clinical trials) to meet a number of requirements, including access control procedures, user identity verification, tracking of performed actions, and more. When planning your project, make sure to carefully study relevant compliance requirements and incorporate them into the design of your data management solution.
Challenge 4. Lack of talent to handle big data
The pharma sector has traditionally been a slow adopter of technology, so many companies are still lacking the needed talent to realize their ambitious plans. Pharma industry players must think of an appropriate way to close the knowledge gap – be it breeding in-house talent or turning to external teams.
Instead of a conclusion
Big data in pharma presents vast opportunities for innovation, efficiency, and improved patient outcomes. As the market for pharmaceutical big data continues to grow, companies are embracing this transformative technology to stay competitive.
If you seek to unlock the true power of big data and drive breakthroughs in drug development, contact our experts, and we will answer any questions that remain unanswered.
The post Big Data in Pharma: What It Is and How It’s Used appeared first on Datafloq.
