Arguably the most popular method of extract, transform, load (ETL) is using Kafka. Configuring Kafka for ETL, data pipelining or event streaming can be challenging but there are better tools.
Confluent delivers the most complete distribution of Kafka, improving it with additional community and commercial features designed to enhance the streaming experience of both operators and developers in production and at massive scale. Couchbase, as a highly available distributed and highly scalable data platform, and Confluent seems like a match made in heaven. But how do you move data in and out of Couchbase through Confluent?
Couchbase supports a Kafka/Confluent sink/source connector that can be managed within the Confluent Control Panel.
Enable the Couchbase Sink Connector
Adding the Couchbase connector can be accomplished several ways from a local Confluent install as well as Confluent Hub download. See the documentation for installing and configuring the connector links.
Once the connector is added in the Confluent Control Panel, the Connect tab should look like this:
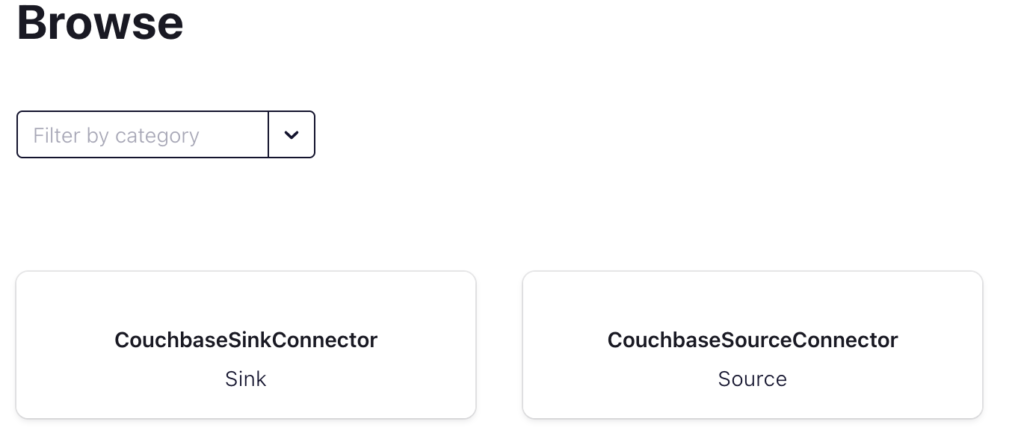
Confluent Connect with the Couchbase Sink and Source Connector
Clicking on CouchbaseSinkConnector displays the following dialog:
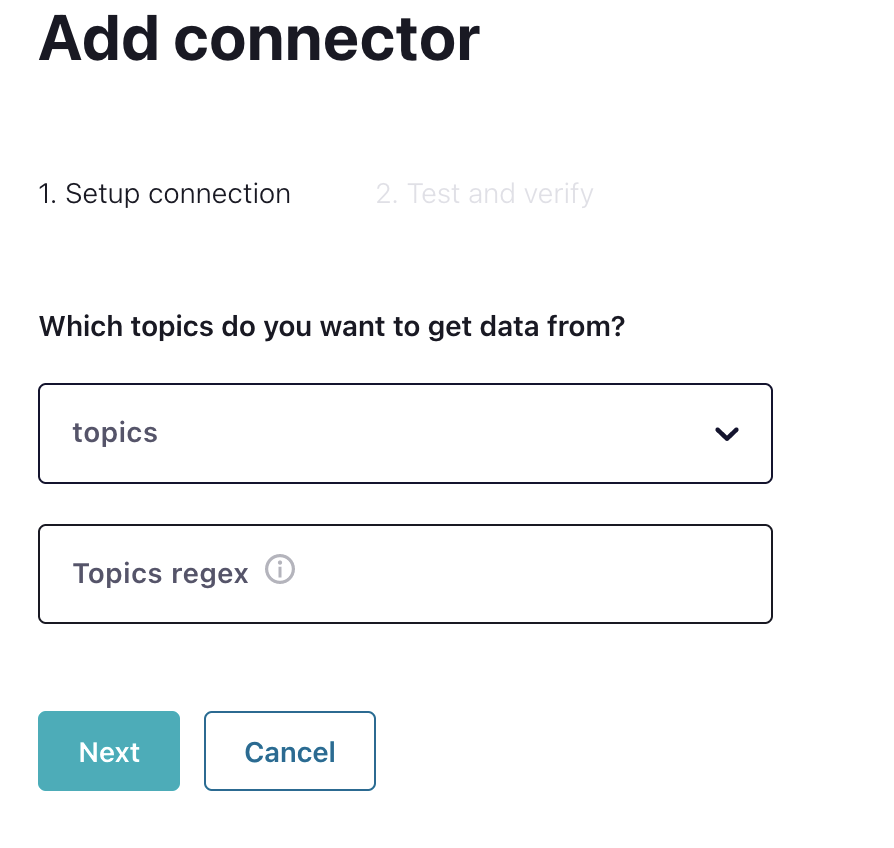
Selecting the topic configured in Confluent will populate all the fields to configure the connector. The fields are Couchbase-specific fields for mapping topics to Couchbase. Fundamentally, Couchbase stores data in buckets, scopes, and collections.
Setting topic for stream
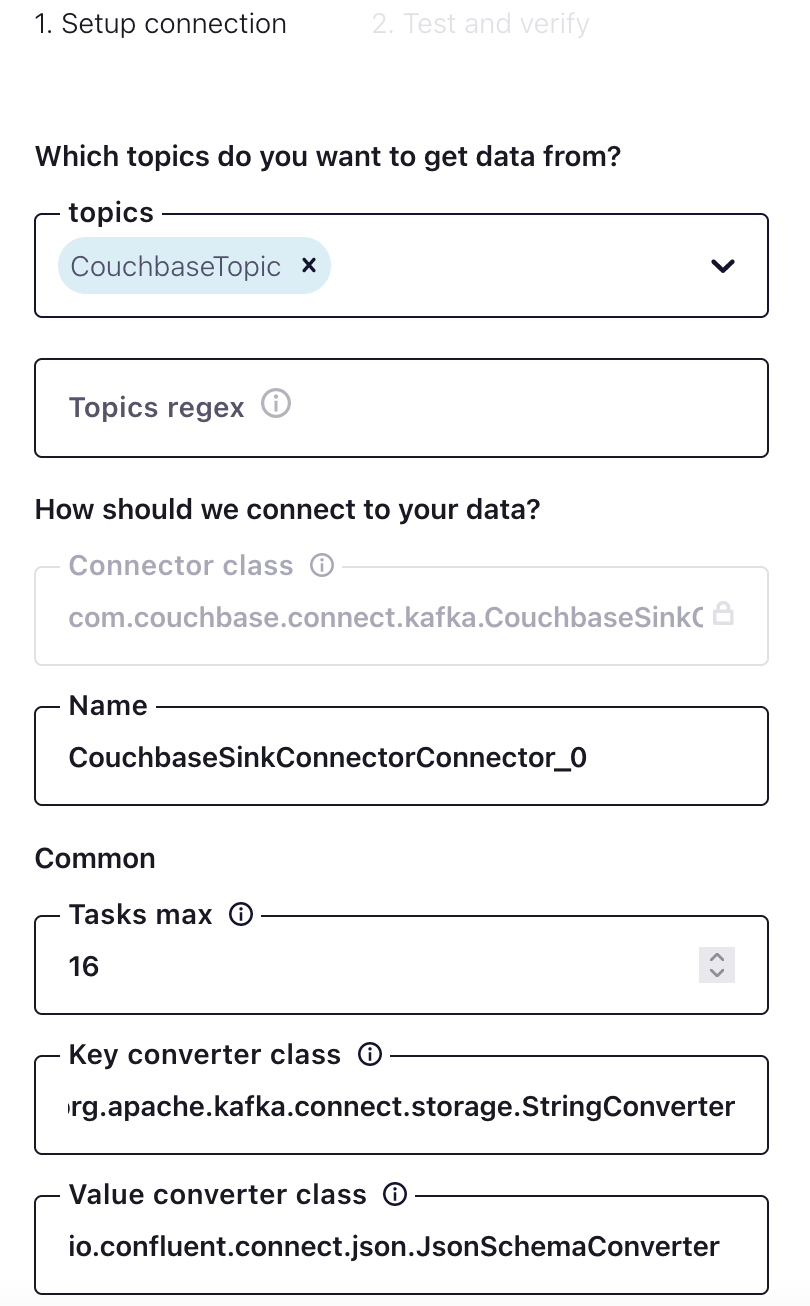
CouchbaseTopic was created in Confluent with 16 partitions. Under the Common section for Tasks max, one can think of those as threads for the connector, e.g. 16 tasks. In this case, there is a one-to-one mapping between partitions to tasks for high performance. This value is not a requirement, for instance, there could be 16 partitions and 32 tasks but be mindful of the resources of the hosting machine.
Selecting a Couchbase bucket as sink
The next step is the connection to Couchbase which is straightforward.
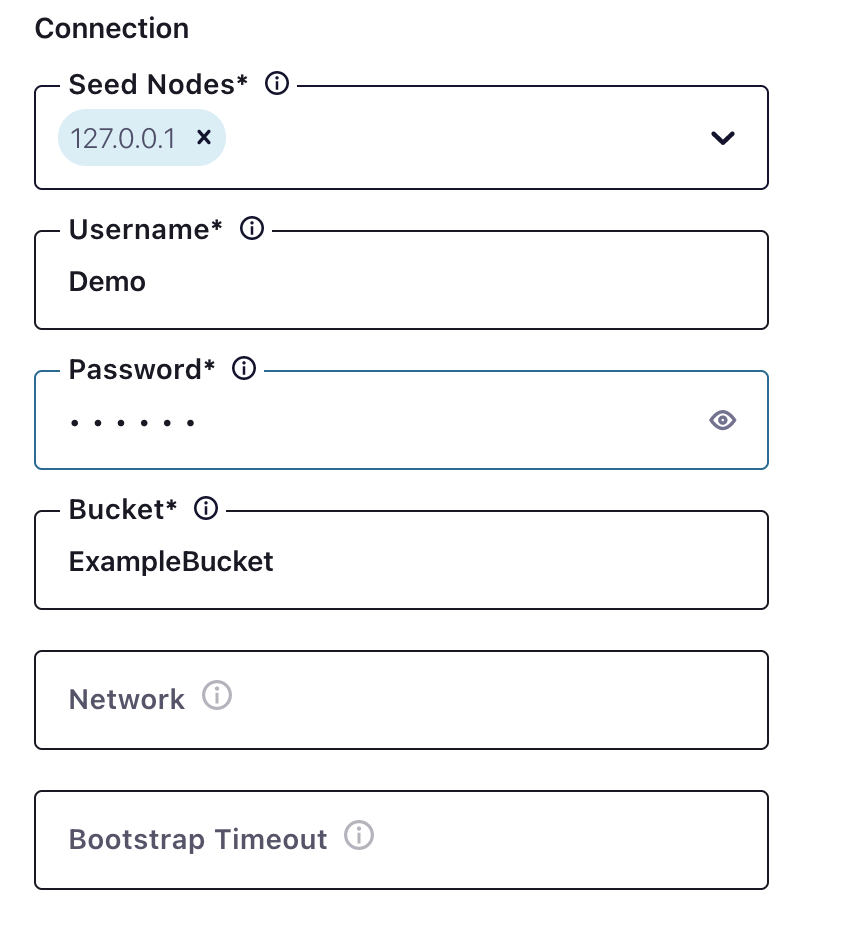
In this case, the seed node is localhost but that can be either hostname or IP.
Remember – the user for the bucket must have access rights in Couchbase for the bucket, scopes, and collections!
After configuring the connection let’s look at scopes and collections.
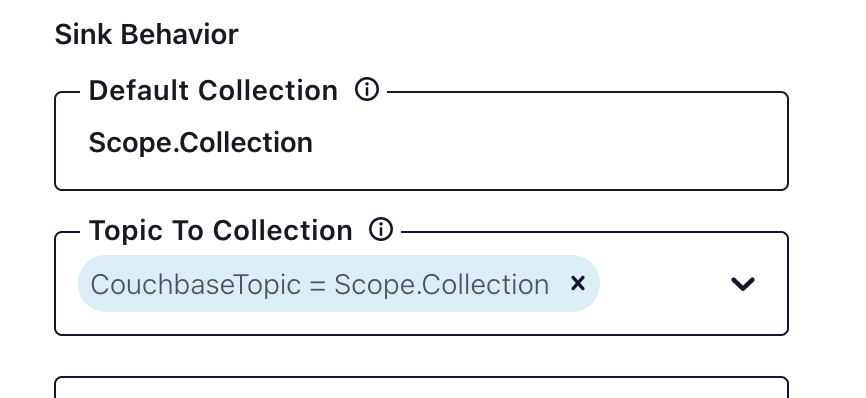
Above is an example of how to configure scopes and collections. It is important to ensure that the scope and collection exists in Couchbase with adequate permissions.
When creating the topics in Confluent consider the bucket–>scope-->collection mapping – each topic will map to a scope/collection. If there is more than one scope and collection being mapped then there needs to be specific topics created for the mapping.
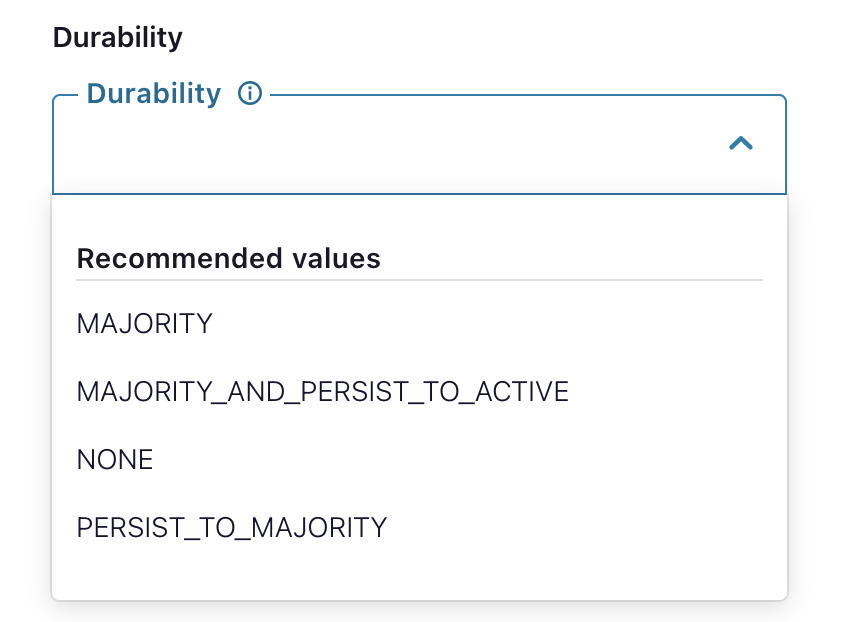
Specific Couchbase durability settings
Durable writes can be configured for the Couchbase connector as outlined below:
The Couchbase Connector can be configured for varying serialization and deserialization data types, such as straight JSON or AVRO binary. Let’s look at AVRO binary compression.
AVRO compression is a binary compression that can be deserialized into JSON using a schema. This schema maps the binary to a JSON structure. The Couchbase connector can deserialize with one schema that is configured in Confluent. Confluent will do the serialization and deserialization, then the topic will be populated with the serialization output. Confluent can support one schema natively through Control Center. If there are multiple steps in serialization then a schema registry needs to be created to store the schemas and ordered steps in which schemas are to be used.
Finally the connector is configured.
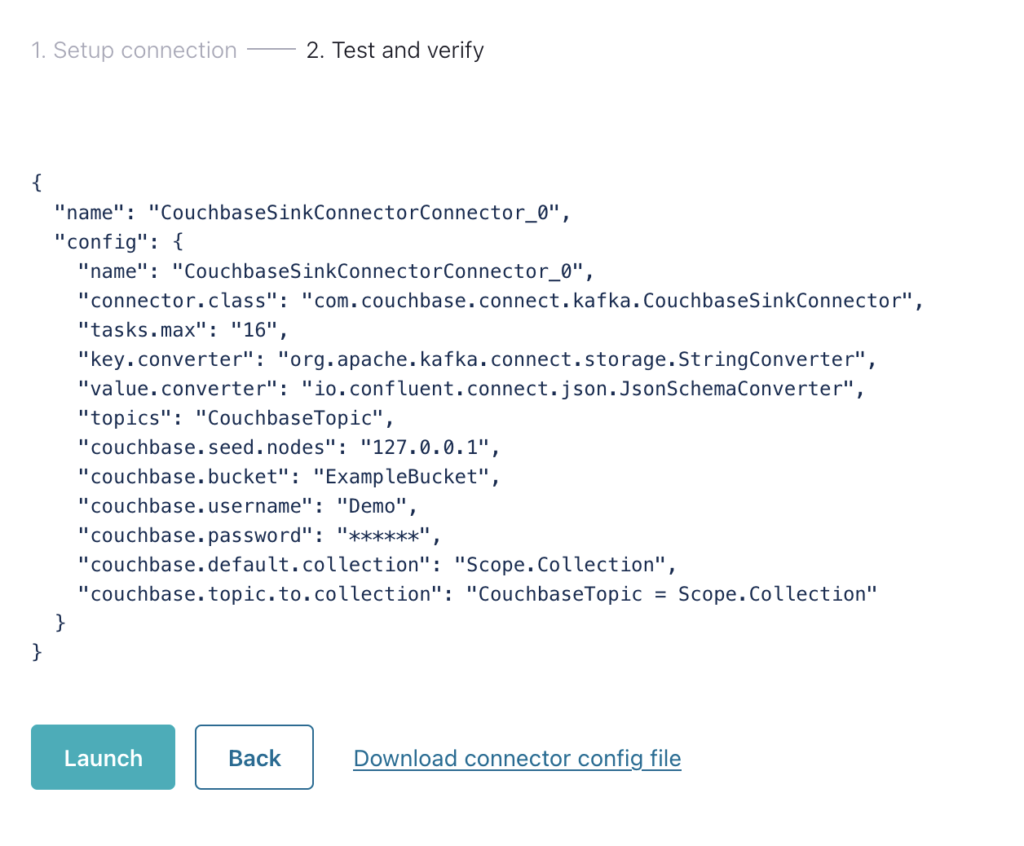
If multiple connectors need to be configured (such as different topics to different scopes and collections), the configuration file can be downloaded and added to the predefined cluster.
The Couchbase Kafka Connector with Confluent is an easy path to ETL and data streaming to and from Couchbase. The source connector is easier to configure as it is just the same connection set up but a mapping of bucket –> scope –> collection to a Kafka topic.
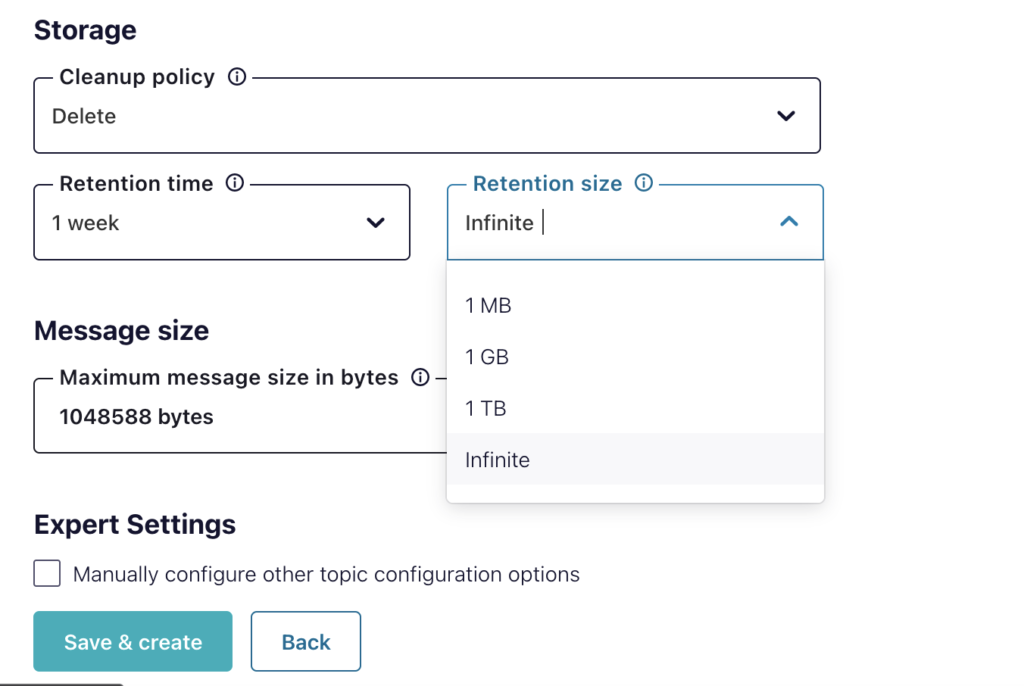
After the connector is up and running it will pick up messages in the topic queue and migrate them automatically into Couchbase as they arrive. Each task will take the latest message in the queue and remove it from the queue, there’s no need for management of the queue other than how long the messages are saved on the queue as shown below:
Next steps and resources
-
- Quickstart for Couchbase Kafka Connector
- GIT repository of Kafka/Couchbase examples, with deep dives into SQL++ integration as well as customizations.
- Confluent Couchbase Connectorchbase/kafka-connect-couchbase
- Integrating Couchbase Capella Data With Confluent Cloud (Video below)
The post How to Configure Couchbase’s Confluent Sink Connector appeared first on The Couchbase Blog.
