The panorama of artificial intelligence, particularly in natural language processing (NLP), is undergoing a transformative shift with the introduction of the Byte Latent Transformer (BLT), and Meta’s latest research paper spills some beans about the same. This innovative architecture, developed by researchers at Meta AI, challenges the traditional reliance on tokenization in large language models (LLMs), paving the way for more efficient and robust language processing. This overview explores the BLT’s key features, advantages, and implications for the future of NLP, as a primer for the dawn where probably tokens can be replaced for good.
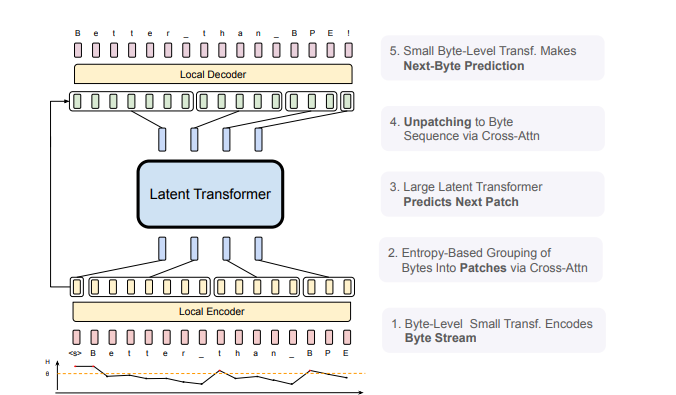
Figure 1: BLT Architecture: Comprised of three modules, a lightweight Local Encoder that encodes input bytes into patch representations, a computationally expensive Latent Transformer over patch representations, and a lightweight Local Decoder to decode the next patch of bytes.
The Tokenization Problem
Tokenization has been a cornerstone in preparing text data for language model training, converting raw text into a fixed set of tokens. However, this method presents several limitations:
- Language Bias: Tokenization can create inequities across different languages, often favoring those with more robust token sets.
- Noise Sensitivity: Fixed tokens struggle to accurately represent noisy or variant inputs, which can degrade model performance.
- Limited Orthographic Understanding: Traditional tokenization often overlooks nuanced linguistic details that are critical for comprehensive language understanding.
Introducing the Byte Latent Transformer
The BLT addresses these challenges by processing language directly at the byte level, eliminating the need for a fixed vocabulary. Instead of predefined tokens, it utilizes a dynamic patching mechanism that groups bytes based on their complexity and predictability, measured by entropy. This allows the model to allocate computational resources more effectively and focus on areas where deeper understanding is needed.
Key Technical Innovations
- Dynamic Byte Patching: The BLT dynamically segments byte data into patches tailored to their information complexity, enhancing computational efficiency.
- Three-Tier Architecture:
- Lightweight Local Encoder: Converts byte streams into patch representations.
- Large Global Latent Transformer: Processes these patch-level representations.
- Lightweight Local Decoder: Translates patch representations back into byte sequences.
Key Advantages of the BLT
- Improved Efficiency: The BLT architecture significantly reduces computational costs during both training and inference by dynamically adjusting patch sizes, leading to up to a 50% reduction in floating-point operations (FLOPs) compared to traditional models like Llama 3.
- Robustness to Noise: By working directly with byte-level data, the BLT exhibits enhanced resilience to input noise, ensuring reliable performance across diverse tasks.
- Better Understanding of Sub-word Structures: The byte-level approach allows for capturing intricate details of language that token-based models may miss, particularly beneficial for tasks requiring deep phonological and orthographic understanding.
- Scalability: The architecture is designed to scale effectively, accommodating larger models and datasets without compromising performance.
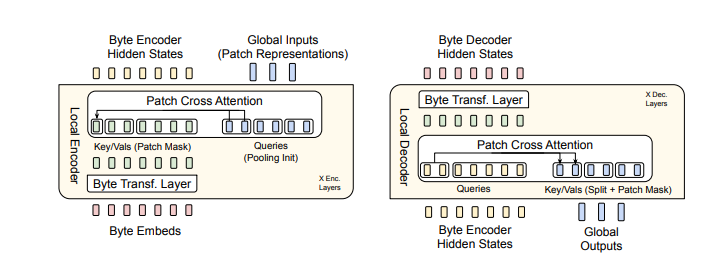
Figure 2: BLT utilizes byte n-gram embeddings along with a cross-attention mechanism to enhance the flow of information between the Latent Transformer and the byte-level modules (see Figure 5). In contrast to fixed-vocabulary tokenization, BLT dynamically organizes bytes into patches, thereby maintaining access to byte-level information.
Experimental Results
Extensive experiments have demonstrated that the BLT matches or exceeds the performance of established tokenization-based models while utilizing fewer resources. For instance:
- On the HellaSwag noisy data benchmark, Llama 3 achieved 56.9% accuracy, while the BLT reached 64.3%.
- In character-level understanding tasks like spelling and semantic similarity benchmarks, it achieved near-perfect accuracy rates.
These results underscore the BLT’s potential as a compelling alternative in NLP applications.
Real-World Implications
The introduction of the BLT opens exciting possibilities for:
- More efficient AI training and inference processes.
- Improved handling of morphologically rich languages.
- Enhanced performance on noisy or variant inputs.
- Greater equity in multilingual language processing.
Limitations and Future Work
Despite its groundbreaking nature, researchers acknowledge several areas for future exploration:
- Development of end-to-end learned patching models.
- Further optimization of byte-level processing techniques.
- Investigation into scaling laws specific to byte-level transformers.
Conclusion
The Byte Latent Transformer marks a significant advancement in language modeling by moving beyond traditional tokenization methods. Its innovative architecture not only enhances efficiency and robustness but also redefines how AI can understand and generate human language. As researchers continue to explore its capabilities, we anticipate exciting advancements in NLP that will lead to more intelligent and adaptable AI systems. In summary, the BLT represents a paradigm shift in language processing-one that could redefine AI’s capabilities in understanding and generating human language effectively.
The post Revolutionizing Language Models: The Byte Latent Transformer (BLT) appeared first on Datafloq.
