Newcomers to StreamSets might not know that we have four engines under the Control Hub hood: Data Collector, Transformer for Spark, Transformer for Snowflake, and Mainframe Collector. This fact... Read more »
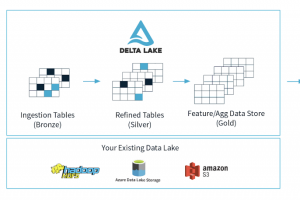
Data warehouses and data lakes are the most common central data repositories employed by most data-driven organizations today, each with its own strengths and tradeoffs. For one, while data... Read more »
Many StreamSets Data Collector customers are now migrating their Hadoop ingestion pipelines to cloud platforms like AWS and they want to take full advantage of the AWS native services... Read more »
StreamSets Data Collector (SDC) supports 69 sources, including relational and no-SQL databases, on-prem and cloud file systems and a handful of messaging applications (documentation). Yet, occasionally, customers ask if... Read more »

The business climate today feels a bit like a battleground, and everyone’s feeling the pressure. A recession looms, competition is fierce, ongoing supply chain issues wreak havoc, and customer... Read more »

Data federation tools are often touted for their ability to unify and query data in a variety of sources and formats using virtualization. The technology, the theory goes, provides... Read more »
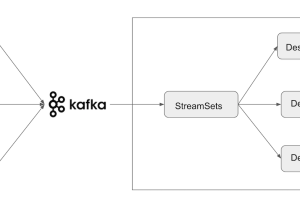
In this post, we will take a look at best practices for integrating StreamSets Data Collector Engine (SDC), a fast data ingestion engine, with Kafka. Then, we’ll dive deep into... Read more »
Raise your hand if you’ve ever had a line of business user go rogue and create a dataset without telling you. Don’t be shy… You’re in good company. In... Read more »

Cloud data migration is on the rise, with cloud adoption expected to nearly double in the next five years. It’s no surprise that cloud data migration is increasing, as... Read more »
Standing for Extract, Transform, and Load, the acronym ETL describes the process of extracting data from a target, transforming it, and sending it on to load into a destination.... Read more »
