It’s no secret that there’s been explosive growth in data over the last decade, with exponentially more created daily. It comes from software, cameras, sensors, activity trackers, satellites, and many other data sources, generating data in a variety of different formats. And processing it all calls for big data pipelines.
A big data pipeline efficiently caters to today’s highly varied, voluminous, and high-velocity data. It can connect to multiple data sources, scale to accommodate growing data volumes, and offer broad compatibility for ingesting data from multiple sources.
In this article, we’ll explore big data pipelines in detail.
What Is a Big Data Pipeline?
Big data pipelines are like everyday data pipelines, helping move data from one point to another, transforming it before it reaches its destination. However, these everyday data pipelines become unreliable when data systems experience sudden growth or a need to add more data sources arises. Downtime or performance degradation can occur. Hence the need for big data pipelines.
A big data pipeline offers businesses the following advantages:
- Scalability: Big data pipelines can serve large and growing data sets, which is crucial for growth as its architecture automatically scales to accommodate business-changing needs.
- Flexibility: Health, finance, banking, construction, and other large organizations today rely on many data sources; these sources rarely produce data of a single data type. Big data pipelines can ingest and process structured, unstructured, and semi-structured data, and process this data in streams, batches, or other methods.
- Reliable architecture: Most big data pipelines use cloud technology to build a highly tolerant, distributed architecture that ensures continuous availability to mitigate the impacts of any failure along the pipeline.
- Timely data processing: These pipelines offer real-time processing, allowing businesses to ingest and extract insights quickly for timely decision-making.
Components of a Big Data Pipeline
A big data pipeline typically involves several components, each responsible for specific tasks within the data processing flow.
- Data sources are the data origins, where data lives, and the primary extraction point. Popular data sources include streaming devices like IoT and medical wearables, APIs, databases like CRMs, and files. These data sources produce data of numerous types, like CSV, JSON, or XML.
- Data ingestion/extraction: This component extracts the data from sources using an ingestion or ETL tool or data integration platform. Your choice of ingestion tool depends on the data sources and the type of data generated by the sources.
- Data storage: After extraction, data is transported to a central storage repository before use in analysis, ML, or data science cases. However, these storage locations may vary depending on the business use case. For example, data may be stored in an intermediate storage/Operational Data Store (ODS) to serve business transactional purposes for providing a current and updated data state for more accurate business reporting. Furthermore, you can store the data in target storage locations like data warehouses or lakes to serve other business intelligence and analytics purposes.
- Data processing is where raw data is transformed into a high-quality, clean, and robust dataset. This component performs numerous data tasks and may involve constructive (adding or replicating data), destructive (removing null values, outliers, duplicated data), or structural (renaming fields, combining columns) data transformation tasks to prepare data for analytics.
- Data analysis and visualization: This component uses different methods like statistical techniques, ML algorithms, and others to identify patterns, relationships, and trends existing within your data and communicates the results in digestible, accessible, and readable formats like graphs, charts, or models.
- Workflow: Workflow defines how every step in your pipeline should proceed. Orchestrators manage the order of operations, handle failures, and do scheduling.
- Monitoring: Monitoring ensures the health, performance, and success of your pipeline. Automated alerts to pipeline administrators when errors occur are important.
- Destination: Your pipeline destination may be a data store, data warehouse, data lake, or BI application, depending on the end-use case for data.
The specific components you’ll use can vary based on the unique requirements of the project, existing technical infrastructure, data types and sources, and the specific objectives of the pipeline.
Big Data Pipeline Architecture
Depending on your business needs, your big data pipeline architecture may be any of the following:
Streaming Data Architecture
Streaming architecture serves businesses requiring ultra-low latency for their transactions. Streaming architecture pipelines process data in real-time, allowing companies to act on insights before they lose value. Financial, health, manufacturing, and IoT device data rely on streaming big data pipelines for improving customer experiences via segmentation, predictive maintenance, and monitoring.
Batch Architecture
Unlike streaming architecture, batch architecture extracts and processes data on defined intervals or a trigger. This is best for workloads/use cases with no need for immediate data analysis, like payroll processing, or for e-commerce businesses for handling inventory at intervals.
Change Data Capture
CDC is employed in streaming architecture. It helps keep systems in sync while conserving network and compute resources. Every new ingestion only loads newly changed data since the last ingestion instead of loading the entire data set.
Lambda Architecture
Lambda architecture is a hybrid method that combines streaming and batch processing for processing data. However, pipeline management becomes very complex because this architecture uses two separate layers for streaming and batch processing.
Key Considerations When Building Big Data Pipelines
Building your big data pipeline involves answering multiple questions regarding data quality, safety, governance, errors, and relevance for business use, thus making pipeline design challenging. Some factors to consider include:
- Adaptability and scalability: Imagine a business that provides financial trading information to users via an application. What happens if such an application suddenly goes viral? Will your pipeline be able to handle all the new users? What if you need to add new features? Your pipelines’ adaptability and easy scalability ensure that systems remain operational despite increased demand. Thankfully, most cloud providers use a distributed architecture today that allows dynamic scaling; compute and storage resources can process and churn out analytics-ready data on demand.
- Broad compatibility with data sources and integration tools: As data sources increase, integrating these new sources may pose risks, causing errors that affect pipeline performance downstream. Selecting tools with broad compatibility that seamlessly integrate and can handle a wide range of data sources is vital.
- Performance: Performance is greatly dependent on latency, and depending on your business goals, the need for timeliness for data delivery differs. For example, manufacturing, health, finance, and other industries that rely on immediate, real-time insights require ultra-low latency to make sure operations proceed smoothly. Ensuring no delays in extracting data from the source is vital to maximizing the performance of your pipelines. Businesses employ CDC mechanisms to update their data based on time stamps, triggers, or logs.
- Data quality: Your data product and quality of analytics are only as good as the quality of your data, and numerous data challenges, like the presence of bad data, outliers, and duplicated data, affect your pipeline. Employing mechanisms to catch these, data drift, and other issues that challenge the quality of your data preserves the effectiveness and accuracy of analytics results.
- Security and governance: Your pipeline needs to be secure, keeping malicious attackers at bay while providing access to authorized individuals. Preventive measures like access and privacy controls, encryption while data is in transit and at rest, tracking, and audit trailing help secure and track access history for your business data. Furthermore, employing masking for PII protects sensitive customer and client information.
- Cost optimization: Building and maintaining data pipelines is a continuous process, requiring updates and reconfiguration to improve efficiency further, especially with business data changes and volume increases. For example, the need for more storage and compute resources translates to more cost as your business evolves. In this case, engineers and key stakeholders must decide on prioritizing and channeling engineering resources to avoid skyrocketing costs within a short time.
- Data drift: Data drift breaks your pipeline and often reduces the quality of analytics or predictive accuracy of your ML models. Data drift results from unexpected changes in the structure or semantics of your data and can break your pipelines. Smart data pipelines offer a way to mitigate this, as they detect any schema/data structure changes and alert your team if any new data violates your configured rules.
- Reliability: Reliability ensures your pipelines proceed as expected, without errors or interruptions. Modern data pipelines employ a distributed architecture that redistributes loads in failover cases to ensure continuous availability. The reliability of your pipelines requires selecting the right tools, continuous monitoring and validation, end-to-end visibility, and automating steps in your pipeline. Also, providing validation checkpoints at various stages along your pipeline guarantees quick mitigation of errors that affect quality, accuracy, and performance.
Examples of Big Data Pipelines in StreamSets
StreamSets offers you numerous patterns to get you started on developing pipelines to unlock data value through its simple, graphical user interface. Let’s explore sample big data pipelines one can build using StreamSets, from ETL to streaming and migration pipelines.
Spark ETL Pipeline With Transformer Engine
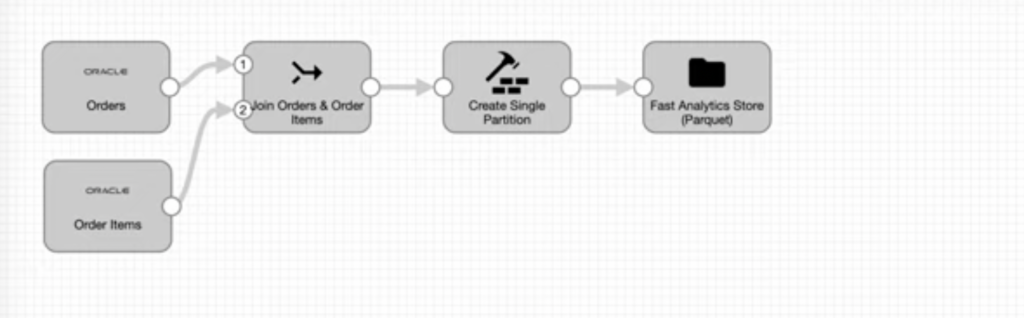
Build and maintain your ETL pipelines in any Spark environment using the transformer engine. This pipeline ingests Oracle order and order items data, joins them, applies a partition processor on the newly joined data, and then stores the freshly processed data in Parquet format.
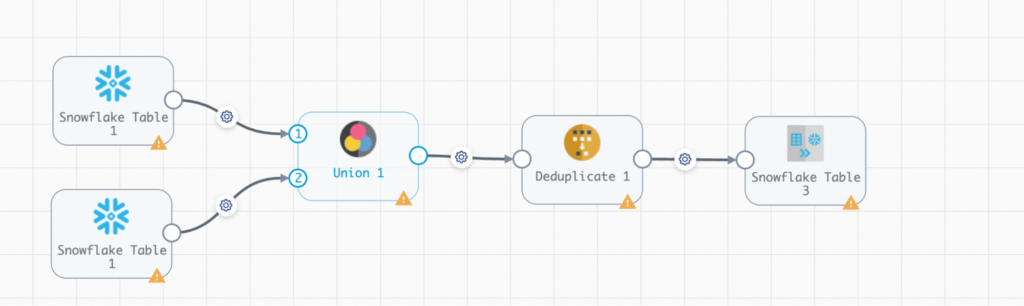
Snowflake ETL Pipelines With StreamSets Transformer for Snowflake
Level up your cloud data ingestion and transformation using StreamSets Transformer for Snowflake. This sample pipeline ingests Snowflake data from two Snowflake tables. It then combines this data, transforms it by removing duplicates using Snowpark native processors, and stores the newly transformed data in a new Snowflake table.
Note: To proceed, you must configure Snowflake, and provide your login credentials.
How StreamSets Simplifies Building Big Data Pipelines
StreamSets offers a user-friendly platform that empowers your data engineering team to build and manage big data pipelines. From using fragments to building pipelines from scratch, the data integration platform allows you to create ETL, streaming, batch, and CDC pipelines to serve different business use cases. Its single mission control panel offers end-to-end visibility, allowing you to view the progress of your pipeline lifecycle.
StreamSets ensures that only high-quality data becomes available for your analytics efforts.

The post What Is a Big Data Pipeline—And Why It Matters appeared first on StreamSets.
