Decision tree learners are powerful classifiers that utilize a tree structure to model the relationships among the features and the potential outcomes. This structure earned its name due to the fact that it mirrors the way a literal tree begins at a wide trunk and splits into narrower and narrower branches as it is followed upward. In much the same way, a decision tree classifier uses a structure of branching decisions that channel examples into a final predicted class value.
In this article, we demonstrate the implementation of decision tree using C5.0 algorithm in R.
This article is taken from the book, Machine Learning with R, Fourth Edition written by Brett Lantz.
There are numerous implementations of decision trees, but the most well-known is the C5.0 algorithm. This algorithm was developed by computer scientist J. Ross Quinlan as an improved version of his prior algorithm, C4.5 (C4.5 itself is an improvement over his Iterative Dichotomiser 3 (ID3) algorithm). Although Quinlan markets C5.0 to commercial clients, the source code for a single-threaded version of the algorithm was made public, and has therefore been incorporated into programs such as R.
The C5.0 decision tree algorithm
The C5.0 algorithm has become the industry standard for producing decision trees because it does well for most types of problems directly out of the box. Compared to other advanced machine learning models, the decision trees built by C5.0 generally perform nearly as well but are much easier to understand and deploy. Additionally, as shown in the following table, the algorithm’s weaknesses are relatively minor and can be largely avoided.
Strengths
- An all-purpose classifier that does well on many types of problems.
- Highly automatic learning process, which can handle numeric or nominal features, as well as missing data.
- Excludes unimportant features.
- Can be used on both small and large datasets.
- Results in a model that can be interpreted without a mathematical background (for relatively small trees).
- More efficient than other complex models.
Weaknesses
- Decision tree models are often biased toward splits on features having a large number of levels.
- It is easy to overfit or underfit the model.
- Can have trouble modeling some relationships due to reliance on axis-parallel splits.
- Small changes in training data can result in large changes to decision logic.
- Large trees can be difficult to interpret and the decisions they make may seem counterintuitive.
To keep things simple, our earlier decision tree example ignored the mathematics involved with how a machine would employ a divide and conquer strategy. Let’s explore this in more detail to examine how this heuristic works in practice.
Choosing the best split
The first challenge that a decision tree will face is to identify which feature to split upon. In the previous example, we looked for a way to split the data such that the resulting partitions contained examples primarily of a single class. The degree to which a subset of examples contains only a single class is known as purity, and any subset composed of only a single class is called pure.
There are various measurements of purity that can be used to identify the best decision tree splitting candidate. C5.0 uses entropy, a concept borrowed from information theory that quantifies the randomness, or disorder, within a set of class values. Sets with high entropy are very diverse and provide little information about other items that may also belong in the set, as there is no apparent commonality. The decision tree hopes to find splits that reduce entropy, ultimately increasing homogeneity within the groups.
Typically, entropy is measured in bits. If there are only two possible classes, entropy values can range from 0 to 1. For n classes, entropy ranges from 0 to log2(n). In each case, the minimum value indicates that the sample is completely homogenous, while the maximum value indicates that the data are as diverse as possible, and no group has even a small plurality.
In mathematical notion, entropy is specified as:
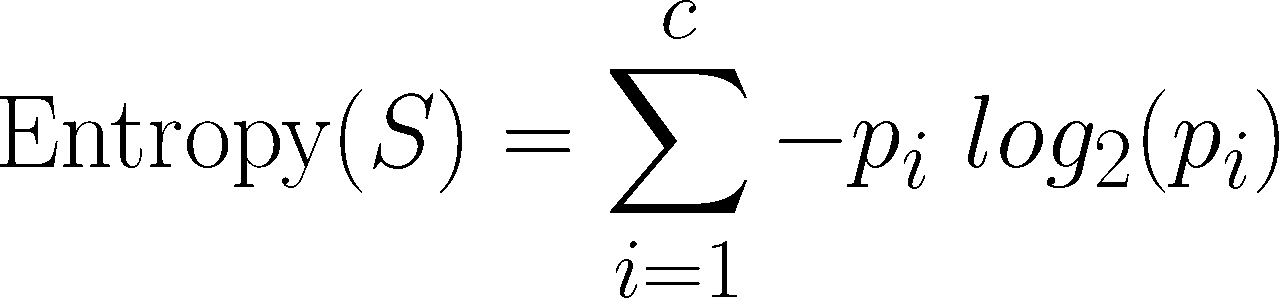
In this formula, for a given segment of data (S), the term c refers to the number of class levels, and pi refers to the proportion of values falling into class level i. For example, suppose we have a partition of data with two classes: red (60 percent) and white (40 percent). We can calculate the entropy as:
> -0.60 * log2(0.60) - 0.40 * log2(0.40)[1] 0.9709506
We can visualize the entropy for all possible two-class arrangements. If we know the proportion of examples in one class is x, then the proportion in the other class is (1 – x). Using the curve() function, we can then plot the entropy for all possible values of x:
> curve(-x * log2(x) - (1 - x) * log2(1 - x), col = "red", xlab = "x", ylab = "Entropy", lwd = 4)
This results in the following figure:

The total entropy as the proportion of one class varies in a two-class outcome
As illustrated by the peak in entropy at x = 0.50, a 50-50 split results in the maximum entropy. As one class increasingly dominates the other, the entropy reduces to zero.
To use entropy to determine the optimal feature to split upon, the algorithm calculates the change in homogeneity that would result from a split on each possible feature, a measure known as information gain. The information gain for a feature F is calculated as the difference between the entropy in the segment before the split (S1) and the partitions resulting from the split (S2):
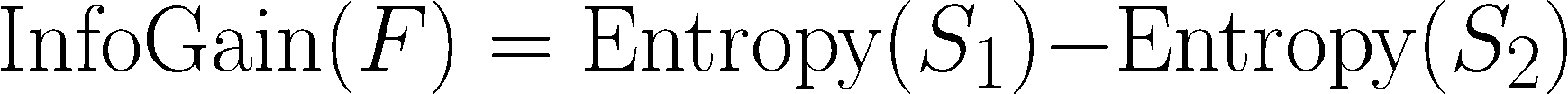
One complication is that after a split, the data is divided into more than one partition. Therefore, the function to calculate Entropy(S2) needs to consider the total entropy across all of the partitions. It does this by weighting each partition’s entropy according to the proportion of all records falling into that partition. This can be stated in a formula as:
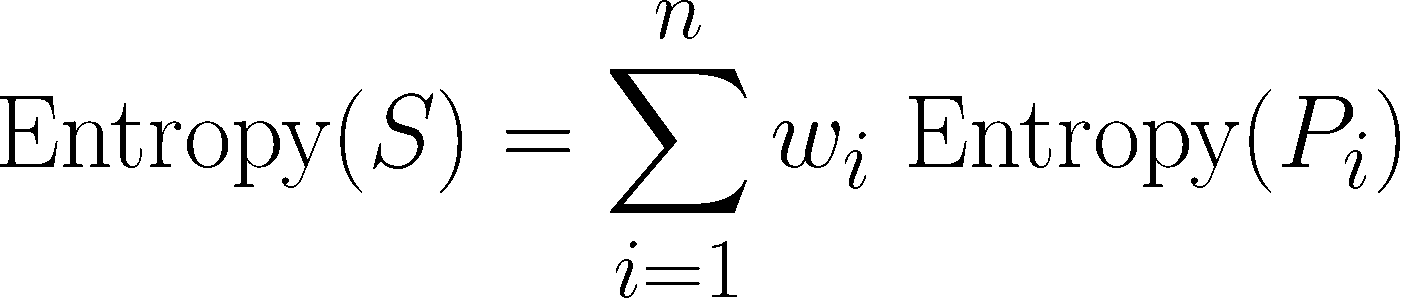
In simple terms, the total entropy resulting from a split is the sum of entropy of each of the n partitions weighted by the proportion of examples falling in the partition (wi).
The higher the information gain, the better a feature is at creating homogeneous groups after a split on that feature. If the information gain is zero, there is no reduction in entropy for splitting on this feature. On the other hand, the maximum information gain is equal to the entropy prior to the split. This would imply the entropy after the split is zero, which means that the split results in completely homogeneous groups.
The previous formulas assume nominal features, but decision trees use information gain for splitting on numeric features as well. To do so, a common practice is to test various splits that divide the values into groups greater than or less than a threshold. This reduces the numeric feature into a two-level categorical feature that allows information gain to be calculated as usual. The numeric cut point yielding the largest information gain is chosen for the split.
Note: Though it is used by C5.0, information gain is not the only splitting criterion that can be used to build decision trees. Other commonly used criteria are Gini index, chi-squared statistic, and gain ratio. For a review of these (and many more) criteria, refer to An Empirical Comparison of Selection Measures for Decision-Tree Induction, Mingers, J, Machine Learning, 1989, Vol. 3, pp. 319-342.
Pruning the decision tree
As mentioned earlier, a decision tree can continue to grow indefinitely, choosing splitting features and dividing into smaller and smaller partitions until each example is perfectly classified or the algorithm runs out of features to split on. However, if the tree grows overly large, many of the decisions it makes will be overly specific and the model will be overfitted to the training data. The process of pruning a decision tree involves reducing its size such that it generalizes better to unseen data.
One solution to this problem is to stop the tree from growing once it reaches a certain number of decisions or when the decision nodes contain only a small number of examples. This is called early stopping or prepruning the decision tree. As the tree avoids doing needless work, this is an appealing strategy. However, one downside to this approach is that there is no way to know whether the tree will miss subtle but important patterns that it would have learned had it grown to a larger size.
An alternative, called post-pruning, involves growing a tree that is intentionally too large and pruning leaf nodes to reduce the size of the tree to a more appropriate level. This is often a more effective approach than prepruning because it is quite difficult to determine the optimal depth of a decision tree without growing it first. Pruning the tree later on allows the algorithm to be certain that all of the important data structures were discovered.
Note: The implementation details of pruning operations are very technical and beyond the scope of this book. For a comparison of some of the available methods, see A Comparative Analysis of Methods for Pruning Decision Trees, Esposito, F, Malerba, D, Semeraro, G, IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, Vol. 19, pp. 476-491.
One of the benefits of the C5.0 algorithm is that it is opinionated about pruning-it takes care of many of the decisions automatically using fairly reasonable defaults. Its overall strategy is to post-prune the tree. It first grows a large tree that overfits the training data. Later, the nodes and branches that have little effect on the classification errors are removed. In some cases, entire branches are moved further up the tree or replaced by simpler decisions. These processes of grafting branches are known as subtree raising and subtree replacement, respectively.
Getting the right balance of overfitting and underfitting is a bit of an art, but if model accuracy is vital, it may be worth investing some time with various pruning options to see if it improves the test dataset performance.
To summarize , decision trees are widely used due to their high accuracy and ability to formulate a statistical model in plain language. Here, we looked at a highly popular and easily configurable decision tree algorithm C5.0. The major strength of the C5.0 algorithm over other decision tree implementations is that it is very easy to adjust the training options.
The post Implementing a decision tree using C5.0 algorithm in R appeared first on Datafloq.
