A robust data view is often the driving force behind effective, data-driven growth decisions. With organizational data residing in multiple data sources like Customer Relationship Systems (CRM), Enterprise Resource Planning (ERP) systems, IoT devices, and social media, there’s a need for a centralized data store to help unify and give you a thorough view of your data for business decision-making. Enter the Enterprise Data Warehouse (EDW).
An EDW helps simplify your data consolidation efforts by acting as a storage repository for all organizational data residing in disparate data sources for powering market decisions. Your EDW can house one or more smaller data warehouses depending on the organization’s size.
Let’s explore the EDW architecture, its types, and how they differ, building an effective team to cater to your EDW, and how StreamSets helps enable your EDW architecture.
What Is an Enterprise Data Warehouse?
An enterprise data warehouse is an integrated storage repository that houses all business data from multiple sources for business intelligence and analytics efforts to create actionable insights that drive business operations and accurate decision-making. Like a data warehouse, the EDW houses structured historical data, making it essential for identifying trends over time to inform future business strategies. However, an EDW houses more business data and is more architecturally complex than your typical data warehouse.
3 Types of Data Warehouse Architectures
Regardless of your implemented data warehouse architecture, all data warehouses are column-oriented, storing data as rows, and can perform complex analytical queries on business historical and current data for reporting and analytics. Depending on your data needs, budget, and complexity, there are three data warehouse architectures:
- Single-tier architecture: This is the simplest and oldest form of data warehouse and is primarily suitable for handling smaller datasets. This architecture has the reporting layer or schema connected directly to the data warehouse without smaller data marts separating them. Although great for reducing redundant data, it reduces query performance as queries run against the entire dataset instead of a subset.
- Two-tier architecture: This architecture employs multiple data marts between the data warehouse and reporting layers. The existence of multiple data marts helps split the dataset into smaller subsets, each catering to a department or project. Splitting the dataset into subsets helps improve query performance but runs the risk of users accessing business data from the database layer.
- Three-tier architecture: This architecture further separates the client serving layer (front-end) from the database serving layer by adding a middle tier (business layer). This middle tier varies, depending on the business needs, but can be application servers or monitoring servers. This architecture enables easy scaling, as every layer can be scaled independently, and improves security, as further separating the database layer from the client layer reduces the chances of users accessing unauthorized data. However, the extra layer adds more complexity to the architecture design and maintenance.
Cloud Data Warehouse
The cloud data warehouse includes SaaS options like Snowflake, Amazon Redshift, Google BigQuery, or Microsoft Azure SQL Data Warehouse which uses a cloud provider to collate and store your organizational data. Most businesses operating today use the cloud data warehouse for the following reasons.
- Ease of adoption: Adopting the cloud data warehouse comes at no cost of acquisition and configuring software and hardware. Businesses only need to specify their data storage and computing needs to get started.
- Faster and easy scaling: The cloud data warehouse usually has three layers; the storage, compute, and serving layers. This separation of layers helps save cost and, as any increase in demand for storage means scaling only the storage layer instead of scaling all three layers simultaneously, which attracts more cost. Additionally, most cloud providers offer dynamic scaling to add resources automatically when needed. This ease is otherwise tricky for an on-premise data solution where servers and other hardware must be acquired before scaling efforts.
- Global access for distributed teams: Your cloud data warehouse offers flexibility and faster access to teams, regardless of location. The global availability and reach are especially beneficial to distributed teams with members scattered worldwide but need access to organizational data.
- Economical cost of adoption and management: most cloud providers utilize pay-as-you-go pricing, ensuring users only pay for services used. Hence, it is vital to continuously monitor your cloud services to shut off any unused services to avoid inflating your cloud costs.
- Security: Many cloud providers offer robust security features to protect your data as it flows into and out of your data warehouse. These measures include data encryption at rest and in transit or masking, among other standard measures to meet compliance and security standards, such as SOC2, PCI, HIPAA, and GDPR. Always check to make sure your provider, storage method, and data structure are compliant before sharing vital or protected data.
However, shifting from on-prem data warehouses to the cloud can be a challenging data migration task.
Data Marts
Data marts represent smaller project-oriented data warehouses. A data mart has limited scope, existing to serve the needs of a particular department or project rather than an entire organization. For example, the finance, HR, and marketing departments could each have their own data marts to serve their department needs. Likewise, data teams responsible for internal analytics, employee retention, or inventory optimization might each have their own data mart.
A data mart helps reduce the time to access business data as relevant departments can directly access the smaller, decentralized data warehouses instead of digging through irrelevant data from the enterprise data warehouse or aggregating from multiple sources. Additionally, data marts help improve the performance of queries, as any query runs against a subset of data, as opposed to against the entire data warehouse dataset.
Data marts can be dependent, independent, or hybrid, depending on how the data flows to populate the data mart:
- Dependent data marts: In this type of data mart, data flows from the centralized data warehouse into the data marts. The data warehouse serves as the control house managing the data flow, thus requiring less technical complexity for management from the data mart. However, this dependence on the data warehouse for data management means any downtime or unavailability affects the data mart too.
- Independent data marts: Independent data marts is the opposite of dependent data marts. Data from CRM and ERP systems, social media, and external APIs flow to populate this data mart. Managing this data flow into and within this type requires extensive technical skills for effective governance and postulates that a data warehouse is optional. However, any need for a robust, 360 view of data would need a system to aggregate data from the multiple data marts to ensure accurate, timely reporting.
- Hybrid data marts: This data mart mixes independent and dependent data marts and uses data warehouses and a collection of sources as its data inputs. This data mart is helpful for data integration whereby data sources initially populate the data marts, and when the data proves to be helpful, it flows into the data warehouse.
Enterprise Data Warehouse
An enterprise data warehouse acts as the single source repository for business data.
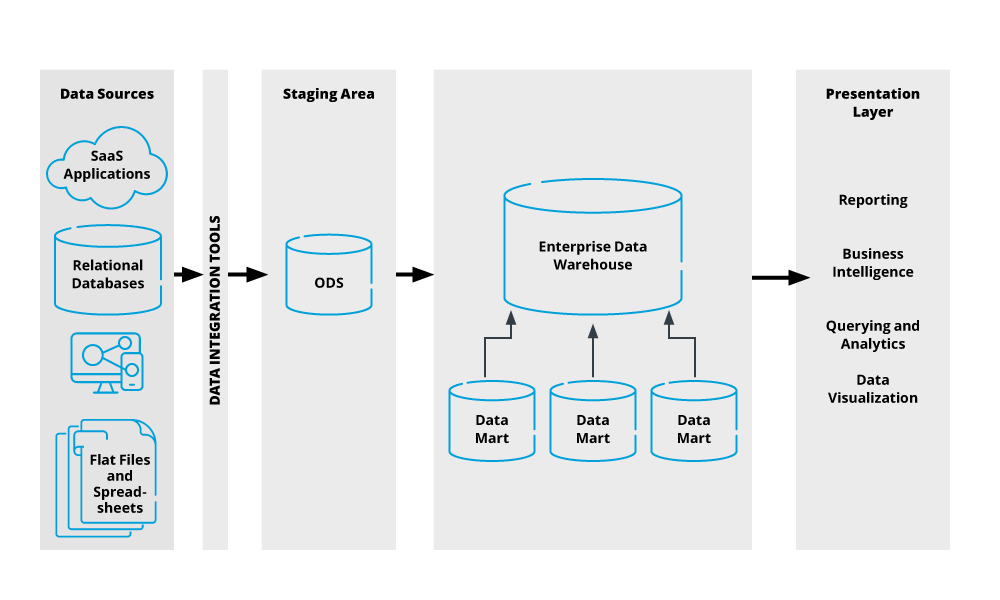
Its architecture can contain the following essential components:
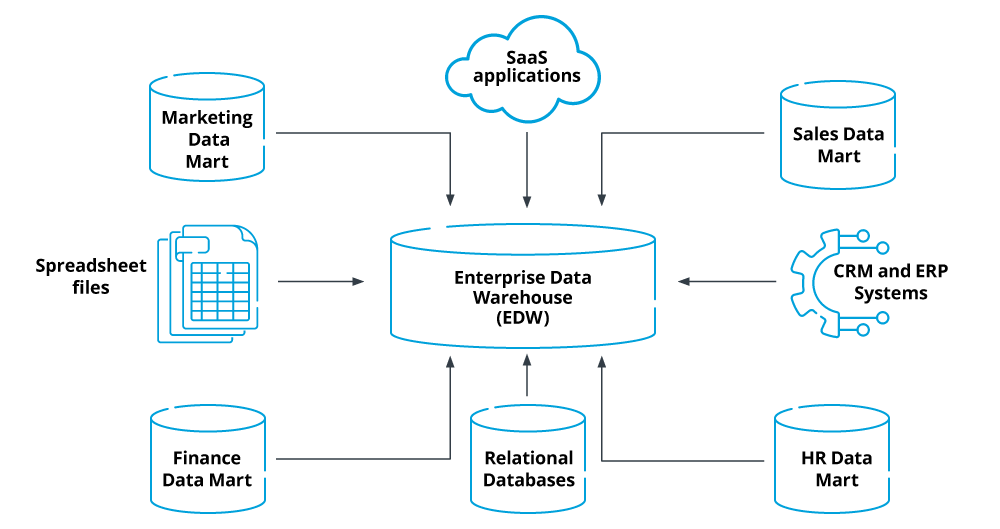
- Data sources: Data sources feed data into your EDW and include SaaS applications, business systems like CRM and ERP systems, IoT applications, and website events data.
- Staging area: Raw data undergoes ETL/ELT processes in this layer to produce high-quality data for loading in the data warehouse. This area performs transformation tasks that clean, filter, and enrich the raw dataset to produce standardized, high-quality data for loading. This staging area may be an operational data store(ODS).
- Storage layer: Newly transformed data is loaded in the data warehouse for storage and analysis.
- Presentation/User-interface layer: This layer enables data users to access and use data present in the EDW for analytics, reporting, and querying purposes.
- Data integration tools and external APIs: These tools help improve the functionality of your data warehouse. Data integration tools help connect to multiple sources, BI software, and other services that help maximize the value of data present in your EDW.
EDW helps automate the collection and integration of data from your business systems for making accurate business decisions that improve growth and revenue. However, the EDW has increased storage costs and may face compatibility issues during integration efforts.
Quick Reference Chart for Data Warehouse Architectures
| Factors | Enterprise data warehouse | Cloud data warehouse | Data marts |
| Data scope | Contains centralized data | Centralized data storage | Contains decentralized data catering to a specific business problem |
| Data sources | All data sources like CRM and ERP systems, social media, websites, data marts | Data sources include CRM, ERP systems, IoT systems, social media, and spreadsheet files. | Data sources vary depending on the type of data mart. For example, dependent data marts rely on data warehouses as their source. |
| Storage requirements | Ranges from 100GB to petabytes of data | Storage requirements depend on business volume and use case but typically exceed 100GB. | Typically between 50GB and 100GB |
| Use cases | Ideal for large organizations handling highly-sensitive data and need data security and privacy | Organizations with distributed teams and limited budgets | Need for faster data access as data is closer to those who need it. |
| Cost | Expensive to set up and maintain due to software and hardware acquisition costs and the need for skilled hands | Cost varies depending on the storage capacity and complexity of analytical queries. | Cost varies depending on the type of data mart. Hybrid data marts are the most expensive as it requires skilled hands in the data mart and warehouse to manage the data flow. |
Enterprise: The Big Brother of the Data Warehouse
The enterprise data warehouse, like the data warehouse, uses integration tools or APIs to collect data from multiple sources and store it as columns for querying and reporting. However, the EDW is a more complex and extensive data warehouse that houses your business’s smaller data warehouses(data marts). The size, business needs, and budget often determine the design of your enterprise data warehouse.
Because the EDW usually sits at the top of your data organizational food chain and provides a comprehensive data view, it requires extensive data management and governance efforts to ensure that only high-quality data is available for decision-making.
The Benefits of an EDW
An enterprise data warehouse provides an organization with the following benefits:
- Centralized data repository: Fragmented organizational data across multiple locations often cause data silos that reduce data access, stifling analysis and business intelligence efforts. An EDW helps reduce this by gathering all the data present in smaller data warehouses, operational data stores, and other data sources, creating a centralized, robust data repository that forms the basis for detailed, business-level reporting and designing effective strategies
- Real-time and historical analysis: EDW collates and stores historical and current data. Analyzing real-time data provide insights for transactional day-day reporting for effective business operations; for example, reporting on the status of an order or responding to customer query data in real-time. Furthermore, analyzing historical data in your EDW can identify trends or patterns in customer behavior or inform on the effectiveness of past strategies that can help inform future decisions.
- Customer personalization: EDW collates data from numerous platforms and offers analysts a comprehensive view of business users. Data analysts can analyze the comprehensive data present in the EDW to get an in-depth, detailed view of customers at various stages of the user journey and create strategies around the information that improve customer satisfaction, engagement, and retention rates.
- Operational efficiency: The robust data view provided by EDW enables effective transactional reporting for driving daily operations. For example, customer support representatives can use data collated from CRM systems and social media to manage customer orders or complaints or inform on the status of certain transactions.
- Faster data access: EDW centralizes data, meaning users only need to access data from it, saving time, reducing technical barriers, and enabling users to do more with the data.
- Improves data quality and consistency: Data undergoes multiple transformation steps before loading into the EDW. This step ensures that only structured, high-quality, and accurate data is available, improving the quality and confidence of your analysis.
Building a Team To Manage Your Enterprise Data Warehouse
Your enterprise data warehouse sits at the top of your data enterprise and is often responsible for serving data to smaller data stores for decision-making. However, building and maintaining the EDW is challenging due to the continuously advancing data requirements and business objectives, hence the need for a dedicated team of experts to handle your EDW configuration and management.
An effective EDW design employs the right mix of highly skilled technical hands and a collection of tools and technologies to handle the data as it flows into and out of the data warehouse.
Technical Team
Your technical team includes data engineers, analysts, architects, and developers who together monitor the health and flow of the data pipelines in your data warehouse. This team possesses comprehensive knowledge of the data in your data warehouse and ensures that only high-quality data is available for consumption.
- Data engineers: Data engineers help design the infrastructure to collect, transform, and store data in your data warehouse. They take note of business needs, budgets, and goals and select tools and technologies to design effective data pipelines for ETL processes to transport and transform data from multiple data sources to your data warehouse.
- Data scientists: Data scientists clean and transform the data for multiple use cases like ML, analytics, and AI. They perform data cleansing, deduplication, aggregation, and other transformation tasks to enrich and create a robust data set for use cases.
- Data analysts: Analysts analyze your data warehouse data using querying languages like SQL to extract insights and present them to important stakeholders via visualization tools to make them understandable for decision-making.
- Data architect: The data architect translates stakeholders’ needs and business objectives into the technical needs of the data warehouse. They review the database design and develop a data warehouse framework while ensuring compliance with data standards and policies.
Tools and Technologies
Tools and technologies can include data integration tools, database sources, and business intelligence and visualization tools for reporting on analyzed data. Your choice of tools depends on your budget, need for customization, and business use cases, among others.
Data integration tools help collect data from multiple sources for transformation and loading into your warehouse. Data Integration tools are crucial for consolidating and migrating data into and out of your EDW. They can perform repetitive tasks that are tasking and time-consuming to data engineers and analysts.
Database sources can be quite varied and can include relational databases, cloud databases like Amazon Redshift, Google BigQuery, and CRM and ERP systems. Sources can also include point of sale systems, IoT sensor data, real-time analytics, and other unique data sources.
Business intelligence and visualization tools can include both internal platforms developed by hand coding for a specific purpose or multi-use cloud-native platforms like PowerBI, Tableau, and Looker.
Simplifying Your EDW With StreamSets
An EDW forms the bedrock of many data-driven organizations for decision-making efforts. However, the need for careful design, continuous maintenance, and a wide variety of data sources and use cases make EDW implementation complex.
StreamSets enables you to build your EDW, or any other data task, using a friendly user interface, a wide variety of built-in connectors, and easy-to-use transformation stages. You can build reusable and extensible data pipelines to create a robust, rich EDW for querying, reporting, and analytics efforts.
Additionally, StreamSets simplifies and improves the efficiency of data migration into and out of EDWs with advanced integration patterns like CDC. StreamSets can be leveraged to reduce redundancies and improve resource utilization when migrating/replicating your data workloads between on-premises and cloud data warehouses.
Find out today how StreamSets can help your organization implement or maintain your EDW or any other data project by getting hands-on with a 30-day free trial of StreamSets.

The post What’s Different About Enterprise Data Warehouse Architecture appeared first on StreamSets.
