More than 80% of the shows people watch on Netflix are discovered through the platform’s recommendation engine. It means that the majority of what your eye lands on is the result of decisions made by a sophisticated machine.
The streaming service relies on artificial intelligence to look at nuanced threads within the content and dive deep into viewers’ preferences. And it’s safe to say: the effort pays off!
If you are still behind the curve but want to improve the experience your customers have with your business, keep on reading. In this blogpost, we guide you through the process of building a recommendation engine and shed light on everything you need to know before turning to AI service vendors.
Recommendation engines 101: things to know before venturing into development
Before we get down to how to build a recommendation engine, let’s look into the types, use cases, and implementation options of one.
The types of recommendation engines
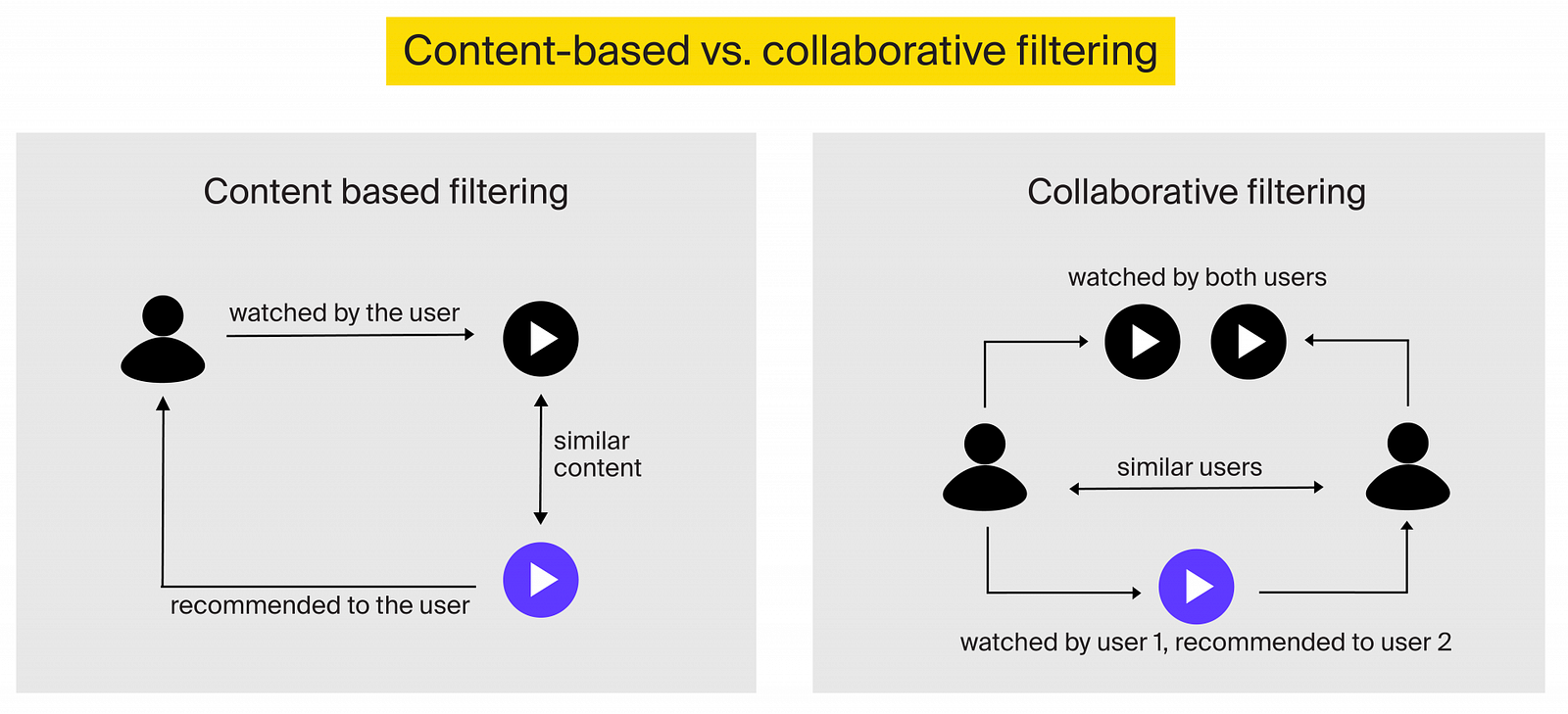
Traditionally, recommendation systems are divided into two broad categories: content-based filtering and collaborative filtering systems.

Content-based filtering
Content-based filtering systems generate recommendations based on the characteristics or features of content. In other words, they recommend products or content similar to those a user has liked or interacted with before. This way, a recommendation engine may suggest “A Farewell to Arms” to a reader who enjoyed “All Quiet on the Western Front” and “Catch-22”.
But how does the engine know which items are similar? Let’s look at Netflix‘s approach to building a recommendation engine to understand that. Although Netflix‘s recommendation system is of hybrid nature, it relies on content similarity to a great extent.
The streaming service has a team of taggers, who watch every new piece of content and label it. The tags range massively from how action-packed the piece is to whether it’s set in space or stars a particular actor. Analyzing the tag data against viewer behavior with machine learning algorithms lets the streaming platform figure out what’s really relevant for each user.
Collaborative filtering
Collaborative filtering systems make recommendations based on user feedback. Such systems assume that users who enjoyed similar items are likely to react similarly to new products and content.
There are two approaches to building a recommendation engine relying on collaborative filtering: user-based and item-based.
With user-based filtering, you create segments of similar users with shared preferences. So, a user is likely to be recommended an item that other users from the segment liked. The features of content are not taken into consideration.
With item-based filtering, the engine creates recommendations based on the similarity of items a user liked to those suggested. Sounds similar to content-based filtering, doesn’t it? Although both content-based filtering and item-based collaborative filtering systems use item similarity to make recommendations, they differ in how they determine what’s similar.
Content-based filtering systems merely recommend items that are similar to the ones a user already liked. With item-based collaborative filtering, you will be recommended an item that is similar to what you liked and that is also liked by the users in your segment.
The use cases of recommendation engines
A high degree of personalization has become a necessity users have come to expect, prompting businesses to enrich their online experiences with recommendation engines. The sectors where recommendation engines have become quite common span:
- Retail and ecommerce: Recommendation engines in ecommerce can do anything from categorizing products to suggesting new items for customers to buy. The impact driven by implementing a recommendation engine in ecommerce and the enhanced customer service, improved marketing, and wider possibilities for upselling that come with it is hard to overestimate. For example, the well-known ecommerce tycoon, Amazon, generates 35% of its revenue with the help of its recommendation system.
- Media and entertainment: From curating playlists to offering personalized suggestions based on past interactions, recommendation engines help media and entertainment platforms engage users for longer by showing them content they would not otherwise discover. Largest media and entertainment platforms, such as YouTube, Netflix, and Spotify, are relying heavily on AI-generated personalized recommendations to attract and retain new users.
- Social media: The social media sector is leveraging the possibilities to provide personalized suggestions as well. Helping users discover similar pages and accounts, social media platforms nudge their users to spend more time interacting with the content, which drives click-through rates and increases revenues.
- Banking and finance: AI-based recommendation systems allow banks to analyze users’ transactions and upsell to increase revenues. For example, when a user buys a flight ticket worth $500, the recommendation engine automatically assumes they are flying abroad and suggests that they buy an insurance travel bundle.

Implementation options to choose from
As you embark on the journey of building a recommendation engine, you’ll encounter several implementation options with their own advantages and considerations, namely:
Plug-and-play recommendation engines
Plug-and-play recommendation engines offer a convenient and hassle-free way to incorporate personalized recommendations into your product or platform. They come pre-built and are designed to seamlessly integrate into your existing infrastructure.
The key advantage of plug-and-play recommendation engines lies in their simplicity and ease of use. They are typically designed to be user-friendly, allowing even non-technical audiences to set them up with minimal effort. Examples of plug-and-play recommendation engines span platforms like Recombee, Seldon, and LiftIgniter.
The downside plug-and-play recommendation engines come with is limited customization and adaptability. While they offer convenience and speed, they may not provide the level of flexibility and fine-tuning that custom solutions offer.
Pre-trained cloud-based recommendation services
Cloud-based recommendation engines allow leveraging the vast computational resources and expertise of cloud service providers. These recommendation services typically provide easy-to-use APIs that allow developers to easily integrate recommendation functionality into their applications.
Cloud-based recommendation engines are highly scalable, too, which allows them to handle large user bases and high traffic loads. Another advantage is continuous improvement as the underlying models are updated and refined by the service providers.
Leading cloud service vendors, such as Amazon Web Services, Google Cloud Platform, and Microsoft Azure, offer pre-trained recommendation services.
The factors to consider when opting for pre-trained cloud-based recommendation services span data privacy, vendor lock-in, and customization requirements. While these services offer convenience and scalability, they may have limitations in terms of customizing the recommendation algorithms to match your specific business needs.
Custom recommendation engines
Custom recommendation engines offer the highest degree of flexibility and control, allowing you to incorporate proprietary algorithms, leverage domain-specific knowledge, and consider the nuances of your data. Going the custom way allows you to capture the intricacies of user preferences, item characteristics, and contextual factors, usually resulting in more accurate and relevant recommendations.
However, while custom recommendation engines offer the most flexibility, they also require substantial development resources, expertise in machine learning, and ongoing maintenance efforts. So, before building a custom recommendation engine, carefully assess your business needs, available resources, and long-term objectives.
The rule of thumb is to go the custom route in the following scenarios:
- You have unique business needs: If your business has unique requirements that cannot be met with off-the-shelf solutions, go custom. It will allow you to tailor the algorithm to your specific task. Say, you’re a niche ecommerce platform selling artisanal products. You may have distinct requirements when it comes to suggesting products: the recommendation engine has to consider factors like product rarity, craftsmanship, and user preferences for specific styles or materials. Building a recommendation engine from scratch will more likely allow you to generate recommendations that align with users’ preferences.
- You want full control and ownership: Building a custom recommendation engine gives you complete control over the entire recommendation generation process: from data preprocessing through algorithm selection to fine-tuning. It allows you to gain full ownership of the system and adapt it as your business evolves without relying on third-party solutions.
- You possess domain-specific knowledge: If you have domain-specific expertise or access to specialized data that can significantly enhance recommendation accuracy, building a custom solution allows you to leverage that knowledge effectively. By developing a tailored recommendation engine, you can incorporate domain-specific features or constraints that may not be available in pre-trained solutions.
- Your application requires high scalability and performance: If you anticipate a massive volume of users or items, have strict latency constraints, or need to process large and complex datasets, building a custom recommendation engine gives you the flexibility to design and optimize the system for maximum scalability and performance. The same applies if you want to generate real-time or near-real-time recommendations.
- You want to gain a competitive advantage: If accurate recommendations are a core differentiating factor for your product or service, building a custom recommendation engine may give you a competitive edge. Investing in a tailor-made solution in this case could provide the opportunity to deliver unique and personalized experiences, enhancing engagement, loyalty, and customer satisfaction.
Building a custom recommendation engine, step-by-step
Providing personalized recommendations is a task typically solved with machine learning. Neural networks can be used, too, however their role is mostly limited to preprocessing training data. Here are the key steps in the process of building a recommendation engine shared by ITRex’s machine learning developers.
Step 1. Setting direction
Kick off development with setting direction for the rest of the project. The essential things to do at this stage include:
Setting goals and defining project scope
Clearly outline what you intend to achieve with a recommendation system and weigh the set goal against resource and budget limitations. For instance, if you want to improve customer engagement and increase sales in your online store, you might keep the project scope limited to recommending products to customers who have already made a purchase. Keeping the scope quite narrow calls for less effort than building a recommendation engine that targets all customers, while the potential for generating ROI stays quite high.
Assessing the available data sources
The performance of a recommendation system depends heavily on the volumes and quality of training data. Before venturing into training, carefully assess if you have enough data points to generate recommendations from.
Defining performance metrics
One of the key challenges of building a recommendation engine that should be accounted for at the very start is defining success metrics. Work out a way of telling if users actually enjoy the newly generated recommendations before you get down to training ML algorithms.
Step 2. Gather training data
The next step in the process of building a custom recommendation system is collecting and preparing data for training machine learning algorithms. To build a reliable recommendation system, you need enough data about user preferences.
Depending on the approach to building a recommendation engine, your focus will shift. When crafting a collaborative filtering system, the data you gather centers around user behavior. With content-based filtering systems, you concentrate on the features of content that users like.
Collaborative filtering
The data about user behavior may come in different forms:
- Explicit user feedback is anything that requires a user to make an effort, like writing a review, liking a piece of content or a product, complaining, or initiating a return.
- Implicit user feedback, like past purchase history, the time a user spends looking at a certain offer, viewing/listening habits, feedback left on social media, and more.
When building a recommendation engine, we advise to combine both explicit and implicit feedback, as the latter allows digging into user preferences that they may be reluctant to admit, making the system more accurate.
Content-based filtering
When collecting data for content-based filtering systems, it is crucial to understand which product/content features you should rely on when digging into what users like.
Suppose you are building a recommendation engine for music lovers. You may rely on spectrogram analysis to understand what type of music a particular user is fond of and recommend tunes with similar spectrograms.
Alternatively, you may choose song lyrics as the basis for your recommendations and advise songs that treat similar themes.
The key is to test and tune in order to understand what works best for you and be ready to continuously improve the initial model.
Step 3. Clean and process the data
To build a high-performing recommendation engine you have to account for changing user tastes. Depending on what you recommend, older reviews or ratings may no longer be relevant.
To prevent inaccuracies, consider only looking at features that are more likely to represent current user tastes, removing data that is no longer relevant, and adding more weight to recent user actions as opposed to older ones.
Step 4. Choose an optimal algorithm
The next step in the process of building a recommendation engine is choosing a machine learning algorithm appropriate for your task. ITRex’s data scientists recommend considering the following ones:
- Matrix Factorization breaks down a large dataset into smaller parts to uncover hidden patterns and similarities between users and items.
- Tensor Factorization is an extension of matrix factorization that can handle higher-dimensional data structures called tensors. It captures more complex patterns by decomposing tensors into latent factors, providing a more detailed understanding of user-item interactions.
- Factorization Machines are powerful models that can handle high-dimensional and sparse data. They capture interactions between features and can be applied to recommendation tasks. By considering feature interactions, they can provide accurate recommendations even when data is incomplete.
- Neighborhood models find similarities between users or items based on attributes or behavior. Particularly effective for collaborative filtering, they build connections among users or items in a network and make recommendations based on preferences of similar users or items.
- Random Walk is a graph-based algorithm that explores connections between items or users in a network. By navigating the network, it captures similarity between items or users, making recommendations based on the captured connections.
- SLIM is a technique used in recommendation systems to understand how items are related to each other. It focuses on finding patterns in the relationships between items and uses those patterns to make recommendations.
- Linear Models predict user-item preferences based on linear relationships between features. While they are easy to understand and quick to train, they may not capture complex patterns as effectively as other approaches.
Also, you may choose from the following deep learning models:
- DSSMs (Deep Structured Semantic Models) learn representations of text or documents. They focus on capturing the semantic meaning of words and their relationships within a structured framework.
- Graph Convolutional Networks are designed for graph-structured data. They operate on graphs, capturing relationships and interactions between the nodes in the graph.
- Variational Auto-Encoder is a generative model that learns representations of data by capturing its underlying latent space. These models use an encoder-decoder architecture to compress data into a lower-dimensional space and reconstruct it.
- Transformer is a model that uses self-attention mechanisms to capture contextual relationships between words in a sentence or document.
What’s important to note is that the methods above are rarely used in isolation. Instead, they are combined via the following techniques and algorithms:
- Ensembling involves training multiple models independently and then combining their predictions through various techniques. Each model contributes equally to the final prediction, and the combination is usually straightforward and doesn’t involve training additional models.
- Stacking takes a more advanced approach. It involves training multiple models, referred to as base models, and then combining their predictions through a meta-model. The base models make predictions based on the input data, and their predictions become the input features for the meta-model. The meta-model is then trained to make the final prediction.
- AdaBoost is an ensemble learning algorithm that improves the accuracy of base models by iteratively training them on different data subsets. The approach focuses on the instances that are difficult to classify correctly and gives them more attention in subsequent training iterations. In each iteration, AdaBoost assigns weights to the training instances based on their classification accuracy. It then trains ill-performing models on the weighted data, where the weights emphasize the misclassified instances from previous iterations.
- XGBoost is an ensemble method that combines weak prediction models iteratively to create a stronger model. It trains models in a sequential manner, where each subsequent model corrects the errors made by the previous one.
Step 4. Train and validate the model
Once you’ve zeroed in on an algorithm for your recommendation engine, it’s time to train and validate the model. Here’s how this step in the process of building a recommendation engine looks like:
To start with, you need to split your data into two sets: a training set and a testing set. The training set, as the name suggests, teaches your model to recognize patterns in user preferences. The testing set helps assess the model’s performance on new data.
With the training set on hand, start training your model. This involves exposing the algorithm to the data, allowing it to learn the underlying patterns and relationships.
After the training phase, it’s time to evaluate the model’s performance using the testing set. This will help you understand how effectively the model generalizes to new data.
Alternatively, you can rely on real-time feedback to understand how well the model is performing. This way, you deploy the model in production and map the generated recommendations to user feedback. Then you move to the next step, where you set the model to adjust its parameters through an iterative learning process.
Step 5. Tune model hyperparameters
Once you have evaluated the model’s performance, you can fine-tune it as needed. Let’s consider an example of a recommendation system built upon a collaborative filtering algorithm.
In collaborative filtering, the number of neighbors determines how many similar users or items are considered when making recommendations. Suppose you are building a recommendation engine that relies on collaborative filtering and suggest new movies. Initially, you set the number of neighbors to 10, meaning that the model considers the preferences of 10 most similar users when generating recommendations.
After evaluating the model’s performance, you find that the precision of the recommendations is lower than desired. To improve that, you decide to fine-tune the model by adjusting the number of neighbors.
To explore the impact of different neighbor sizes, you can run experiments with ranging values. For instance, reducing the number of neighbors to 5 may lead to a significant increase in precision. However, you may notice a slight decrease in recall, indicating that the model is missing out on some relevant recommendations. Increasing the number 20, in turn, might lead to a slight improvement in recall, but suggestions may become less personalized.
The key is to settle for a compromise between precision and recall and strike a balance between capturing diverse user preferences and maintaining accurate recommendations.
Step 6. Implement, monitor, and update the model
With the model primed and ready to roll, it’s time to implement it.
To ensure successful implementation, consider the most effective way to incorporate the model into your existing infrastructure. For instance, you can embed the model into your website’s back end, ensuring that it seamlessly interacts with the user interface. This integration enables real-time recommendations that dynamically adapt to users’ preferences.
Alternatively, you can deploy the model as a service, like a recommendation engine API, that other components of your application can easily call upon. This service-oriented approach ensures flexibility and scalability, allowing your application to leverage the recommendation engine’s capabilities effortlessly.
The implementation phase is also a nice moment to consider how the recommendations will be presented to users. Will they be displayed as personalized suggestions on a website’s homepage, neatly categorized in an intuitive interface? Or will they be seamlessly integrated into the app’s interface, surfacing at just the right moment to surprise users? The choice is yours, but always keep the user experience at the forefront.
Finally, it’s crucial to rigorously test the implemented model to ensure its seamless functionality. Run comprehensive testing to validate its performance and behavior across various user interactions, to ensure the recommendations are accurate, timely, and aligned with user expectations.
The challenges of building a recommendation engine, and how to solve them
Understanding the challenges of building a recommendation engine is crucial for delivering personalized and relevant recommendations. Here’s a rundown of the most common ones:
Challenge 1. Measuring success
One of the key challenges of building a recommendation engine that should be accounted for at the very start is defining success metrics. In other words, before you get down to collecting data and training ML algorithms, you should work out a reliable way of telling if users actually enjoy the newly generated recommendations. This will guide your development process.
Say, you’re a streaming platform. You may count the number of likes or monthly paid subscriptions to measure how well your recommendation engine is performing. However, chances are your recommendations are alright, while users are reluctant to explicitly state their preferences or pay for the service.
The experience of our data scientists shows that user behavior is a more reliable way of measuring recommendation system performance. We wouldn’t doubt a user has enjoyed a show if they binge-watched it in one night, even with no explicit feedback given.
Challenge 2. The curse of dimensionality
Data dimensionality refers to the number of features in a dataset. More input features often make it more challenging to build an accurate recommendation engine. Let’s take YouTube as an example. On the platform, billions of videos and users coexist, and each user is seeking personalized recommendations. However, human and computational resources are limited, while hardly anyone wants to spend hours waiting for recommendations to load.
To tackle this challenge, an additional step, candidate generation, is needed before launching the recommendation algorithm. This step allows narrowing down billions of videos to, say, tens of thousands. And this smaller group is then used for generating recommendations.
Various strategies, with nearest neighbor search being the most prominent one, are used for candidate generation. Other common practices for overcoming the issue of dimensionality include exploring popular categories or preferences shared among people of similar age groups.
Challenge 3. The cold start
Another common problem in the process of building a recommendation engine, the cold start conundrum arises when the system lacks sufficient information about a user or an item, making it challenging to provide accurate recommendations. Overcoming this hurdle involves employing methods such as collaborative filtering, content-based filtering, or hybrid approaches.
Challenge 4. The long tail
Recommendation systems may suffer from a phenomenon known as the “long tail.” This means that popular items receive more attention and recommendations, while less popular ones remain unnoticed by users. Addressing this issue requires generating personalized recommendations and taking individual user preferences into account.
Challenge 5. The cold start for new items
When a new item is added to the system, it has little to no historical data for generating recommendations, making it difficult to create relevant suggestions. One approach to tackle this problem is to use content filters and actively engage users to interact with new items through promotions or advertisements.
Challenge 6. The cold start for new users
Similarly, new users may not have sufficient historical data for accurate recommendations. To overcome this challenge, such methods as content-based filtering, feedback requests, and initial user surveys can be employed.
Challenge 7. Data sparsity
In recommendation systems, data sparsity is a common occurrence where many users rate or interact with a small number of items. This poses a challenge in predicting user preferences. To address this issue, matrix factorization methods incorporating dimensionality reduction, regularization, and other techniques can be used.
To sum it up
Building a recommendation engine is a journey fueled by algorithms, user insights, and iterative refinement. From defining the problem to selecting the right approach through meticulous data preprocessing to model training, each step contributes to the creation of a powerful recommendation system.
A recommendation engine’s ability to understand user preferences and deliver tailored recommendations can hold immense potential for your business. Amazon, YouTube, Spotify, and many other less known, yet no less successful businesses revolutionized their products and subsequently grew revenues with tailored recommendations.
For example, Spotify, a music streaming platform that relies on highly personalized recommendations as the key differentiating factor, continues to grow its user base and revenues each year. Just in Q4 2022, the promise of discovering a new favorite song has brought the platform 20% more monthly active users, resulting in 33 million net additions.
If you are still behind the curve, it is time to harness the power of AI, and revolutionize your user experience with a custom recommendation engine.
Seeking to enhance your solution with a powerful recommendation engine? Talk to ITRex consultants.
The post Building a Custom Recommendation Engine, Explained appeared first on Datafloq.
