Unlocking the power of Large Language Models in data practice: From SQL troubleshooting to natural language querying with LlamaIndex.

Image available to author via unique access to Midjourney the author assumes responsibility for the authenticity.
Over the past few months, there has been a lot of talk about how ChatGPT, and other Large Language Models (LLMs), will change the world. As data professionals, the idea that a machine can provide answers to questions, including business questions, might seem to be an existential threat. But is it?
Large Language Models can be outstanding in providing answers to what is (or what the LLM thinks is true); but by the nature of their training and construction, they are not very good at explaining why something is. LLMs don’t “know” anything about context. They’re really just guessing based on their training.
What Are Data Engineers Really Doing?
According to this Monte Carlo survey, data engineers spend 40% of their workday on bad data. Not only that but:
- An average organization has 61 data incidents a month, taking an average of 13 hours to identify and resolve, totaling 793 person-hours per month.
- 75% of these incidents take between 3 to 8 hours to detect (not resolve).
- Business analysts take an average of 3 hours per day answering data questions.
- Bad data impacts 26% of business revenue.
As data practitioners, our job is to explain why things are the way they are, not just provide the data. Let’s refer to this data — i.e., revenue is up, or jeans are the most common item in a shopping cart — as the “how.” The Monte Carlo survey focuses mostly on detection and discovery, the “how” of the data. We can still out “think” the LLMs and provide the essential part — the “why.” Therefore, let’s use these Large Language Models to do the “how” and spend more time on the “why.”
The “why” is where the true business value is found. Where LLMs can identify a correlation between answers, the “why” is found in identifying causation. Data practitioners can explain that revenue is down because jeans were out of fashion due to the latest Tik Tok trend, or provide the understanding that staffing issues have a downstream effect on customer service NPS scores. LLMs have a hard time identifying this information because it’s not present in their training data.
How Data Practitioners Can Put ChatGPT To Work
To free up your time for that more strategic “why” work, here are some ways ChatGPT and other LLMs can help with the “how” data work.
SQL Query Troubleshooting and Creation
LLMs are essentially guessing based on previous patterns. And what is the most significant pattern that data practitioners follow? SQL.
Troubleshooting SQL
Let’s say you have been given this (poorly written) SQL query:
Select store, category, revenue, revenue-cost AS Net Profit From category_items join store_revenue on category_items.UPC = store_revenue.upc group by category
Ask GPT how to fix it, and you get the following:

Generated Image of a ChatGPT query, provided to author via unique access to ChatGPT; the author assumes responsibility for the authenticity.
Create a SQL Table
How about inserting raw data? We often have data that comes to us as a flat file, and we need to write an insert statement quickly.
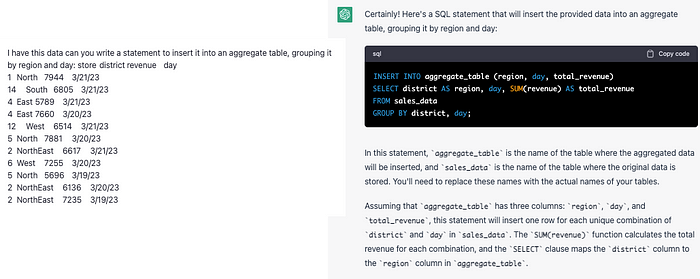
Generated Image of a ChatGPT query, provided to author via unique access to ChatGPT; the author assumes responsibility for the authenticity.
How about handling another common request to aggregate and provide rows for missing data?

Generated Image of a ChatGPT query, provided to author via unique access to ChatGPT; the author assumes responsibility for the authenticity.
Learning and Improvement
Let’s say you get a query from a fellow practitioner, and you don’t understand what it is trying to do, or it uses a function you aren’t familiar with. Ask ChatGPT!
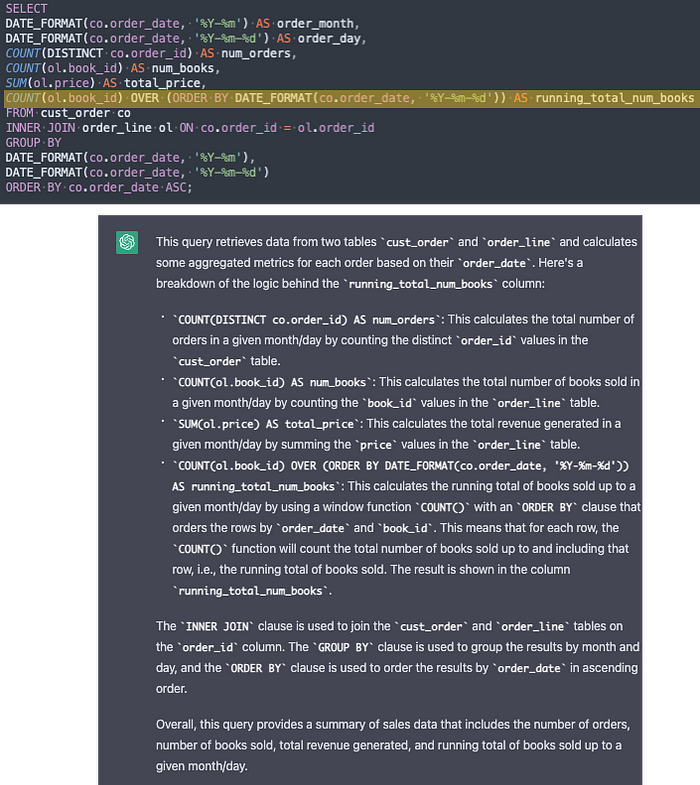
Generated Image of a ChatGPT query, provided to author via unique access to ChatGPT; the author assumes responsibility for the authenticity.
By having LLMs give a jump start to our research and troubleshooting, we can cut down on time spent trying to detect problems with our queries and get to our real value … providing the “why.”
On to the Why: Natural Language Querying of Data
After inserting, troubleshooting, and learning the “how” of the data, how can we use LLMs to help us with the “why?” To successfully communicate with our various stakeholders, it’s helpful to understand the context and language that they are using. This may include business language, understanding of the business, etc. Providing those translations between business language and SQL code can be time-consuming, but they are a critical part of the data practitioner role.
Prerequisite: Metadata
Let’s step back and talk about how Large Language Models work. LLMs, like ChatGPT, have “tokenized” a wide swath of the internet and formed vectors. Think of these vectors as spatial points in a 3D Cube. Something like this:
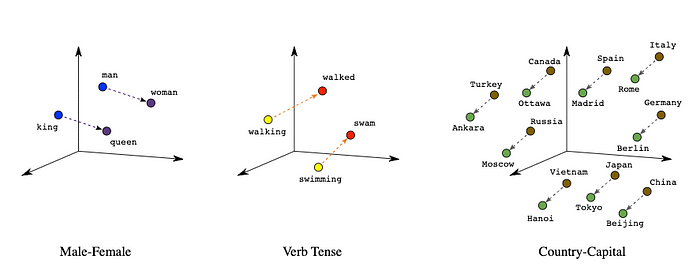
Image Sourced from Google’s Machine Learning Course
So, the LLMs know things are related to each other by their “proximity” within the model. Suppose you want to add additional context; for example, your South Region and Northeast Region are managed by the same person, or that revenue and staffing should be related; you must explain that to the model. This technique is called embedding and is beyond the scope of this article. The critical thing to know is that to apply your business context, you’ll need to convert sources like Data Dictionaries, Business Reports, etc., into a format that the LLM can understand and process.
LlamaIndex
One such tool to help data practitioners is LlamaIndex.
LlamaIndex is a simple, flexible interface between your external data and LLMs. It provides the following tools in an easy-to-use fashion:
- Offers data connectors to your existing data sources and formats (APIs, PDFs, docs, SQL, etc.)
- Provides indices over your unstructured and structured data for use with LLMs.
These indices help abstract away common boilerplate and pain points for in-context learning:
- Storing context in an easy-to-access format for prompt insertion.
- Dealing with prompt limitations (e.g., 4096 tokens for OpenAI’s Davinci model) when context is too big.
- Dealing with text splitting.
- Provides users an interface to query the index (feed in an input prompt) and obtain a knowledge-augmented output.
- Offers you a comprehensive toolset trading off cost and performance.
LlamaIndex is an example of an open-source solution designed to help LLM practitioners with the most challenging part of using ChatGPT … providing the tools to build the context to answer business questions. An exciting application of LlamaIndex is understanding structured SQL data.

LlamaIndex’s ReadMe can be found here
Combining a data warehouse, data lake, and other documents into the training of a natural language chatbot would allow data practitioners to surface data previously unavailable to SQL and data novices in a non-threatening manner while still retaining the “how” that they require to make decisions.
Creating a business context with non-structured SQL and a chatbot in front of your SQL data will help data practitioners better serve their stakeholders. Reducing the barriers between business users and data practitioners will help increase efficiency and provide a self-service environment that can be accessed through natural language, cutting down on the time that data practitioners spend answering questions that are just a SQL query away.
What’s Next?
Congratulations! Hopefully, you’ve reduced your workload and provided more clarity to your stakeholders. So what are the next steps?
We’ve discussed how LLMs work better with more context. The more precise you can be with your prompts and the information you provide, the more likely LLMs will be able to answer accurately.
For example, you could:
- Use applications like ChatPDF to chat with reports from your stakeholders.
- Scrape business information from websites, tokenize it, and use embeddings to fuel your prompts further
- Use Whisper.ai to take “notes” during meetings to add further context
Finally, incorporating these inputs and outputs into your data pipelines can help you productionalize the effort. StreamSets’ excellent SDK can turn SQL queries into repeatable data pipelines. You can also:
- Incorporate the tokenization of new documents into your daily workstreams and data pipelines
- Automate queries that answer the most common questions (i.e., have ChatGPT summarize all of your stakeholder’s questions)
- Help you perform code reviews and explanations with ease
As the capabilities of ChatGPT and its competitors expand and use cases begin to grow, data practitioners can continue to provide value by providing training data and information to the models that boost their value to the company. While Large Language Models can provide summaries, clean SQL code, and even facilitate meeting notes, they can’t turn data into information. After all … they’re just guessing.
The post From Providing Data to Explaining Why: How Large Language Models Are Changing the Role of Data Practitioners appeared first on StreamSets.
