As part of my job, I’m fortunate enough to speak with data leaders far and wide about how they are tackling some of our industry’s biggest challenges, from implementing data mesh to scaling self-service analytics.
What about both? Enter BlaBlaCar, which has made real progress on tough challenges like self service analytics and data mesh over the past few years, leading to a reduction in data incidents and time to insights.
I recently sat down with three of BlaBlaCar’s data leaders to learn from their journey: vice-president of data Emmanuel Martin-Chave, data analytics engineering manager Kineret Kimhi, and senior data engineer Tushar Bhasin. Here’s their story.
BlaBlaCar is the largest transportation marketplace in Europe and Latin America for ride-sharing. The company started as a core app that connected drivers and passengers for carpooling, but today, they support multiple modes of transportation-and immense volumes of complex, peer-to-peer, geographic data.
The data organization at BlaBlaCar makes sure data flows accurately to consumers, product managers, operations teams, marketing teams, and customer support. They also build and productionalize algorithms that automate decision-making. The data team even has a mission statement: to deliver dependable data and algorithms to the company.
To make that happen at scale, the data leaders at BlaBlaCar have adopted a modern data stack and a data mesh platform architecture.
Discovering the data mesh
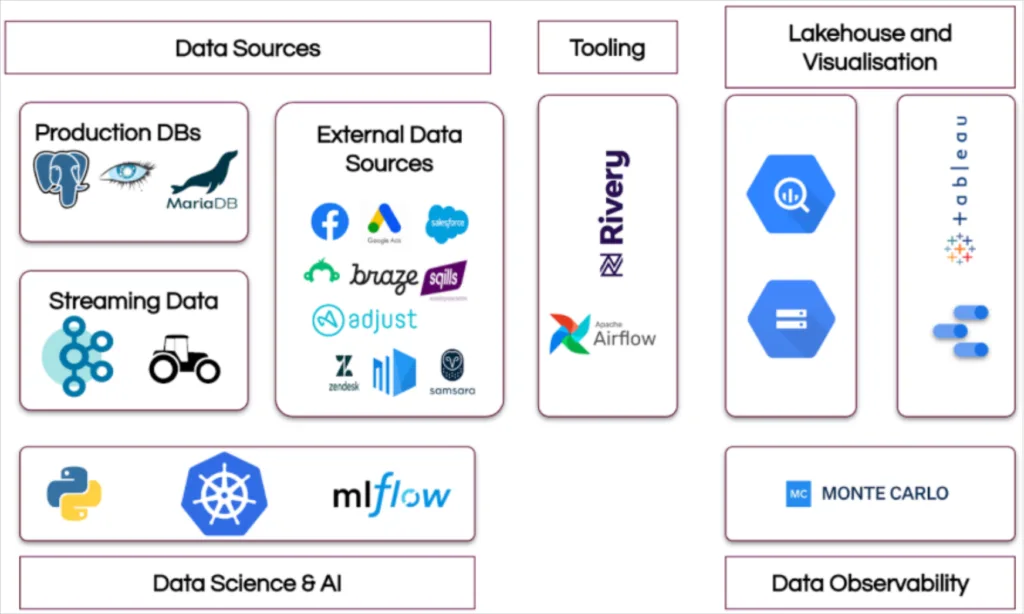 BlaBlaCar’s data stack was built to support their end goal of supporting self service analytics at scale. Image courtesy of BlaBlaCar.
BlaBlaCar’s data stack was built to support their end goal of supporting self service analytics at scale. Image courtesy of BlaBlaCar.
BlaBlaCar has been a data-driven company for a long time. They maintain a modern data stack built on Google Cloud Platform, and as Emmanuel described it, “We have a very strong belief that data-informed decisions create the most long-term value.” Kineret agreed, telling us, “We don’t make any decision without consulting data.”
But in 2018 and 2019, BlaBlaCar took on two large M&As (mergers and acquisitions) that challenged their data team’s speed and quality of work.
“Data quality that cost us hundreds of hours a year just to investigate, fix, and diagnose was no longer possible,” said Emmanuel. “We had some new use cases around data science that were hard to fit into our existing org. That’s essentially what triggered the discussion of ‘We need to do things differently.’”
Up to this point, the BlaBlaCar data organization was designed around skillsets. They maintained a team of data analysts, a team of data engineers, and a team of data scientists. “When you operate that way, structurally, whenever you want to do a project, you require alignment between three to five groups-and that’s super hard to operate,” said Emmanuel.
The team began partnering data scientists and backend engineers to work closely together, forming what Emmanuel describes as “embryonic squads.” Then, Emmanuel encountered Zhamak Deghani’s landmark article on data mesh framework, a type of platform architecture that leverages a domain-driven, self-serve design.
“All of a sudden it clicked into place,” said Emmanuel. “For me, it was the first time that the concepts that exist in engineering-service-oriented architecture, having microservices, and so on-were expressed so clearly and applied to a data structure. I could see how that related to some of the problems we were facing, and it became pretty clear that data mesh was a very interesting approach-and we were probably heading there without knowing it.”
Once the data mesh framework became an apparent solution, the BlaBlaCar data leaders began planning a more formalized rollout, starting with a carefully plotted proof of concept.
Developing-and communicating-a data mesh proof-of-concept
Emmanuel and his team spent a few months planning how to bring data mesh to life at BlaBlaCar. They identified one or two key domains that were relatively isolated from the most complex part of the data stack-reducing risk if the experiment didn’t work-but big enough to learn from. The team started their data mesh proof-of-concept with two domains over a period of three months, reorganizing select data professionals into cross-functional domain teams.
Throughout the planning of the functional scopes, deciding on the POC, and setting the timelines, the data team spent a great deal of time planning out their communication strategy.
Kineret described the questions they would ask themselves: “How are we going to communicate this to everybody? When should we communicate? And not just externally to our stakeholders, but internally to the people who work in these teams-whose teams are essentially going to be drastically moving?”
The leaders were intentional about communicating outward and soliciting feedback, both from external stakeholders and the data specialists working on the POC domain teams.
“The domains gave us feedback that they were delivering faster and working much better together, which was great,” Kinerest said. “At the same time, we got some less-great feedback from practitioners who were feeling isolated. Like a data engineer who used to work with six other data engineers in her team-but now, she’s alone and doesn’t have somebody to peer-review with.”
They addressed these concerns by creating horizontal guild chapters so peers could collaborate and learn together-addressing what they dubbed the lone engineer syndrome-while ensuring the cross-functional domain teams retained their autonomy.
“The driving principle behind how we organize was that we wanted to get to a very strong ownership, and we believe that strong ownership requires autonomous squads,” said Emmanuel. “A team that cannot operate autonomously doesn’t own its scope. You can’t ask someone to fix something if they can’t do it. It’s not going to happen. They’re going to complain. So giving autonomy to the squads was a driving principle to solve for the efficiency we wanted to reach, and it had a tremendous impact on quality and speed.”
The proof of concept worked. But before they could roll out data mesh to the rest of the organization, they needed to ensure all that data was trustworthy and reliable.
Addressing data quality and trust
According to Kineret, “Once you’re in a data mesh, every dependency becomes a bigger liability than when you’re in a monolith.” The data team had already identified problems around data quality and lack of observability, and wanted to solve them before they expanded data mesh architecture.
“We had over 50% of our data quality issues found by our stakeholders,” said Kineret. “Our consumers were telling us, ‘This data does not make sense. Can you please look into that?’ We wanted to minimize the data quality issues that were found by end users-we wanted to see them before anybody else does, and minimize the average time to resolve data quality issues.”
The data team had in-house tooling to manage data quality, but it wasn’t scaling as the company grew. With close to 5,000 tables in production, it had become impossible for data engineers to write tests covering different use cases. And when data issues occurred, there wasn’t always a coordinated response.
According to Kineret, “We had data practitioners of every type and in every team trying to investigate what was wrong, what’s broken, what’s happened here, why does this data not make sense? And that costs a lot. In a data mesh org, that would multiply because different domains might be dealing with the same problem, but they don’t know it. So we wanted to solve this.”
Additionally, BlaBlaCar’s data leaders knew they needed to get ahead of governance to avoid creating new problems with siloed teams. “You’re just going to build teams that are sitting next to each other, don’t work together, and are going to duplicate work,” said Emmanuel.
“In an effective data mesh, data governance tools need to be standardized,” said Kineret. “And part of that is data observability and data quality. Anything around metadata, performance, and quality should be standardized. If you don’t, you’ll deal with soaring prices and increasing budgets because every team will essentially just do what they want. And your stack will look chaotic.”
To scale their data quality across soon-to-be decentralized domain teams, BlaBlaCar decided to invest in data observability. Automated monitoring and alerting for data quality issues, as well as end-to-end lineage of data throughout its lifecycle, provided the visibility and capabilities required to support a decentralized data mesh.
With data quality and governance accounted for, over 18 months, BlaBlaCar reorganized its data professionals into six teams. Five are cross-functional squads of data engineers, analysts, and scientists (along with software engineers to support autonomy), organized in alignment with the company’s product and engineering teams.
The sixth team is a platform team, responsible for the data infrastructure and the governance layer of building common standards and tooling that binds everything together.
“A governance group can look at what squads are doing and point out when Squad A and Squad B are doing the same thing, and need to stop duplicating work,” said Emmanuel. “We meet every two weeks to review common projects and governance guidelines, and that helps us identify these things before they metastasize into bigger problems.”
The results of data mesh: 100+ fewer hours spend per quarter fixing data quality issues
Today, BlaBlaCar’s domain teams have ownership over their data, and work more productively to deliver value to the business. Data quality has improved significantly, with data observability speeding up time-to-detection and time-to-resolution of data issues.
“Right now, we have connected more than 5,000 tables which are being automatically monitored for schema, volume, and freshness,” said Tushar. “Without any human effort, we get alerts if the tables are not fresh, if the volume has suddenly increased or decreased, or if schema changes. It’s provided out-of-the-box, which is a great help.”
The data team also uses nearly 250 custom monitors, including ones that help calculate and measure data KPIs. Domain teams also work within their data observability platform and receive relevant alerts when their data assets are compromised. Data ownership is clear, so only the team responsible spends time working to resolve an issue. And with end-to-end data lineage, it’s easier for domain teams to troubleshoot and solve problems.
“It used to take us more than a few hundred hours to do data quality checks, and most of the time was spent on understanding where the issue was,” said Tushar. “But with [data observability], because of the quick root cause analysis, it helped us a lot.”
“With lineage, it’s much easier to find the root cause or even pinpoint a point in time where it started,” said Kineret. “And then you can trace back to developers and see if there were any version updates. So our time-to-resolution has improved drastically.”
For Emmanuel, the change has led to a much-appreciated decrease in emails and messages from across the company-within a few weeks. “From a VP standpoint, it was fantastic that at some point I stopped being pinged by the rest of the org that there was a data quality issue. That shows that, for our consumers, all of a sudden a big pain disappeared and they weren’t forced to escalate it to me.”
What’s next for data at BlaBlaCar
As the BlaBlaCar data leaders look to the future, they plan to apply more data mesh principles across their teams. They’re working on developing and implementing standardized data KPIs and SLAs, and improving domain-oriented ownership within the data warehouse. Emmanuel also wants to close the gap between data engineers and data consumers.
“Our philosophy is that we need to make the engineering teams responsible for producing the data we consume-we need to make them consume their own data,” said Emmanuel. “Once you close that loop, I think they’ll be much more picky about what they create and put into the system, because they’ll be consuming it themselves and seeing when something is wrong.”
Across their tech stack and team structures, data observability will continue to play a key role. And the BlaBlaCar data leaders advise any teams looking to adopt data mesh to invest early in data quality.
“Data observability is a prerequisite for our data mesh journey, and I think for any data mesh reorg,” Kineret said. “Otherwise, chaos will prevail as every domain is moving in their different direction, trying to deliver as fast as they can without looking sideways.”
The post How BlaBlaCar Built a Practical Data Mesh to Support Self-Service Analytics at Scale appeared first on Datafloq.
