What Is Kubernetes?
Kubernetes is an open-source platform for automating deployment, scaling, and management of containerized applications. It was originally developed by Google and is now maintained by the Cloud Native Computing Foundation.
Kubernetes provides a way to bundle multiple containers, which are isolated environments for running applications, into groups called “pods.” Pods allow for easy scaling and management of containerized applications.
Kubernetes integrates well with a variety of tools and services, including CI/CD pipelines, monitoring and logging solutions, and cloud-native services, making it a versatile platform for DevOps teams. It provides a centralized platform for managing and scaling containerized applications, making it easier for DevOps teams to ensure high availability and performance.
Using Kubernetes for Big Data and Machine Learning
Kubernetes can be a powerful platform for big data and machine learning (ML) workloads. Some of the benefits of using Kubernetes for these use cases include:
- Scalability: Kubernetes allows you to easily scale up or down the number of resources required for your big data or ML workloads, helping you to optimize resource usage and costs.
- Resource management: Kubernetes provides advanced resource management features, such as automatic bin-packing and quality of service (QoS) guarantees, that make it easy to manage the resource requirements of big data and ML workloads.
- High availability: Kubernetes provides built-in support for high availability, allowing you to run your big data and ML workloads on multiple nodes and ensuring that they are automatically rescheduled if a node fails.
- Portability: Kubernetes is designed to run on a variety of infrastructure, including on-premise data centers, public clouds, and edge devices. This makes it easy to deploy and manage your big data and ML workloads in a hybrid or multi-cloud environment.
- Integration with other tools: Kubernetes integrates with a wide range of big data and ML tools, including Apache Spark, Apache Hadoop, TensorFlow, and more. This allows you to build and deploy complex big data and ML workflows on a single platform.
- Easy deployment and management: Kubernetes provides a declarative model for deploying and managing big data and ML workloads, making it easy to automate the deployment and management of these complex systems.
However, it is worth noting that big data and ML workloads can be resource-intensive and require specialized hardware, such as GPUs, to run effectively. As a result, it is important to carefully plan and design your Kubernetes cluster to meet the specific requirements of your big data and ML workloads.
What Is kubectl?
kubectl is a command-line tool for managing a Kubernetes cluster. It is used to deploy, inspect, and manage the resources and components of a Kubernetes cluster, such as pods, services, and configurations. kubectl communicates with the Kubernetes API server to perform operations on the cluster.
With kubectl, users can perform a variety of tasks, such as creating and managing pods, scaling deployments, updating configuration files, and viewing logs and status information. The tool also supports plugins, which can be used to extend its functionality.
One of the key advantages of kubectl is that it provides a consistent interface for managing Kubernetes clusters, regardless of the underlying infrastructure. This makes it easier for users to manage their clusters, regardless of whether they are running on a public cloud, a private cloud, or on-premises.
kubectl Commands to Get Started
Here are some basic kubectl commands for managing Kubernetes clusters and resources.
Listing Resources
To list resources in a Kubernetes cluster using kubectl, you can use the kubectl get command. This command is used to retrieve information about resources in a Kubernetes cluster. It can be used to retrieve information about various resource types, such as pods, services, and configurations. kubectl get supports a number of flags that can be used to customize the information that is retrieved, such as the output format, the namespace, and the selector used to filter resources.
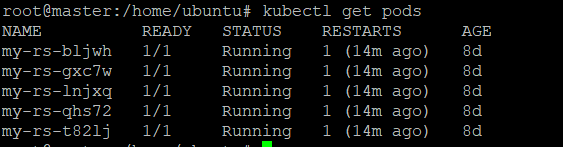
For example, to list all pods in the default namespace, you would run the following command:
kubectl get pods
Describing Resources
The kubectl describe command provides a comprehensive and human-readable representation of the state and configuration of a resource, including its metadata, status, events, and associated resources. For example, to retrieve detailed information about a pod, you would run the following command:
kubectl describe pod <pod-name>
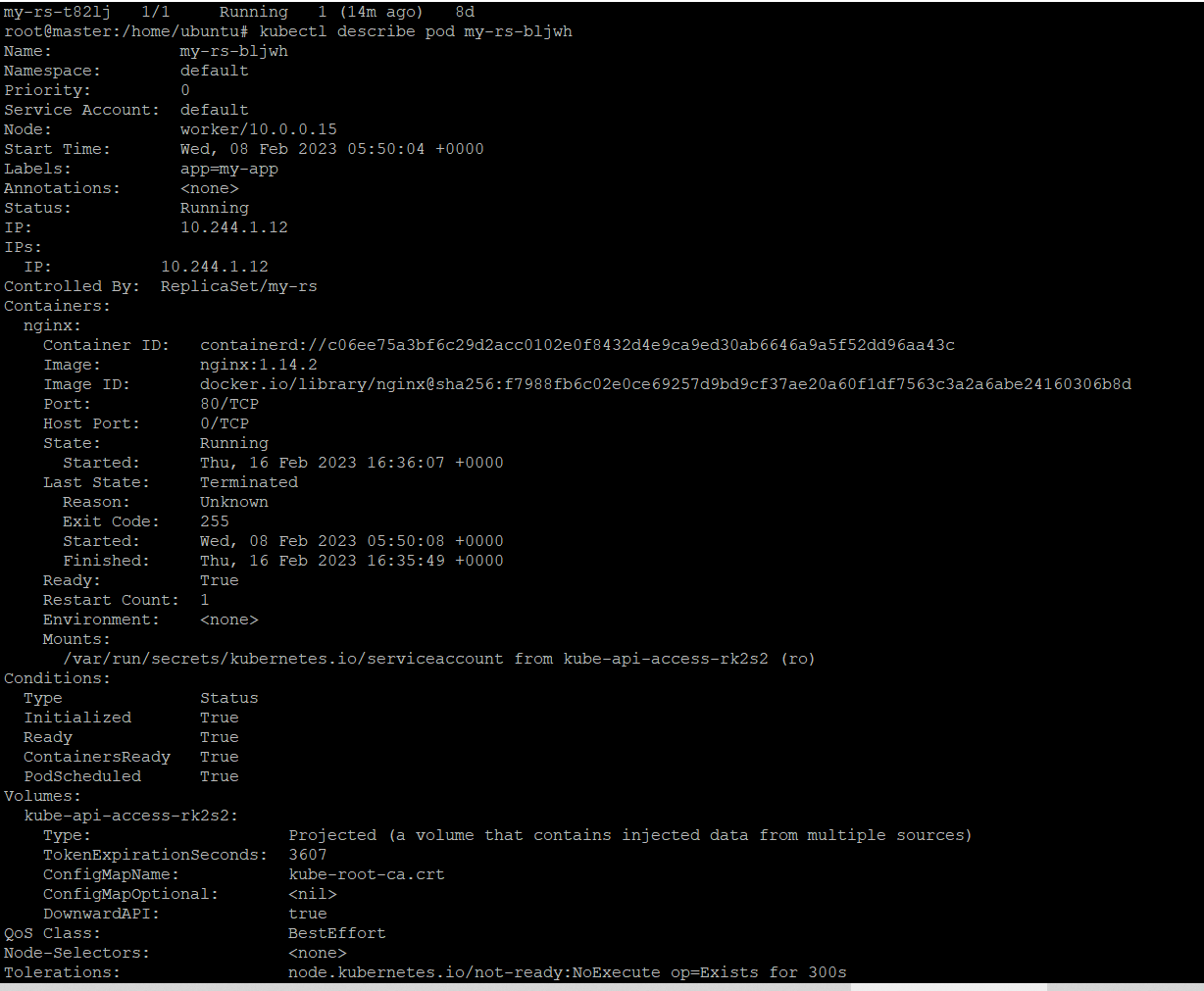
The output of the kubectl describe command includes a wealth of information about the resource, including its metadata, such as labels and annotations, as well as information about its status, such as its IP address and the state of its containers.
Managing Volumes
Here are some of the most commonly used kubectl commands for managing volumes in a Kubernetes cluster:
- kubectl apply: This command is used to create or update resources in your cluster. For example, you can use this command to create a PersistentVolumeClaim (PVC) or a PersistentVolume (PV) that represents a volume in your cluster.
- kubectl delete: This command is used to delete resources from your cluster. For example, you can use this command to delete a PVC or PV.
- kubectl cp: This command is used to copy files and directories between a pod and the local file system. For example, you can use this command to copy data from a volume mounted in a pod to your local file system for backup or analysis.
- kubectl logs: This command is used to retrieve the logs generated by a pod. For example, you can use this command to retrieve the logs generated by a pod that is running a big data or machine learning workload.
Managing Deployments
The kubectl command-line tool provides a number of commands for managing Kubernetes deployments, including:
- Kubectl rollout status deployment/myapp: This command retrieves information about the status of a deployment, including its rollout history and the status of its pods.
- kubectl rollout undo statefulset/myapp: This command rolls back a deployment to a previous revision, undoing any changes that were made to the deployment.
- kubectl rollout history deployment/myapp: This command retrieves the history of a deployment, including information about each revision, such as the date and time it was created and any changes that were made to the deployment.
While these commands are useful for managing deployments, they are often not used in practice because they require manual intervention and can be error-prone. Instead, many organizations use tools like Helm, which provide a higher-level, abstracted interface for managing deployments. With Helm, users can manage deployments using templates and manage their applications as a whole, rather than individual components.
Executing Commands
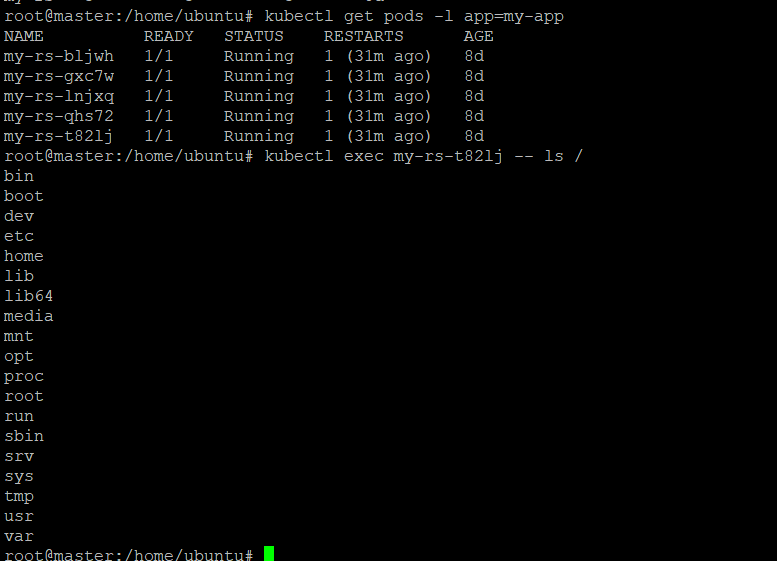
The kubectl exec command is used to execute a command in a running container in a Kubernetes cluster. This can be useful for tasks such as inspecting a container’s file system, running administrative commands, or debugging an application. For example, to run the ls command in a container in a pod named my-pod, you would run the following command:
kubectl exec my-pod — ls /
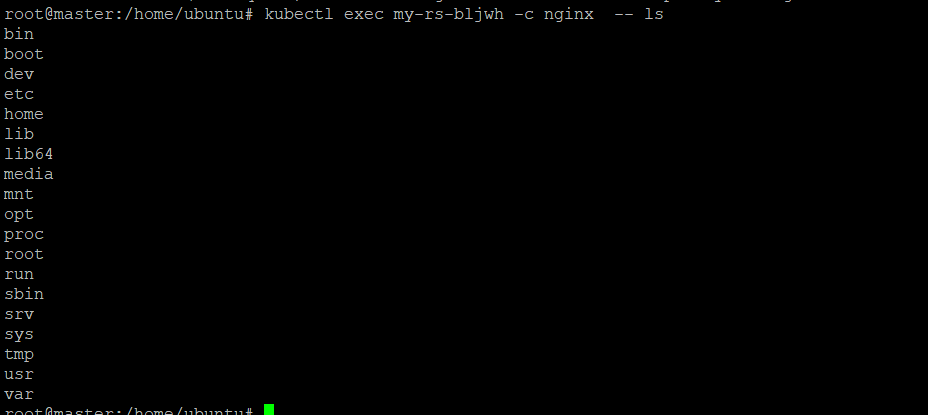
If the pod has multiple containers, you can specify the name of the container you want to execute the command in using the -c flag, like this:
kubectl exec my-pod -c <container-name> — ls /
Conclusion
Kubernetes is an essential tool for data science teams, providing a flexible and scalable platform for managing and deploying data science workloads. The kubectl command-line tool is a key tool for managing a Kubernetes cluster, providing a unified interface for performing a variety of tasks, such as deploying and scaling applications, inspecting resources, and executing commands in containers. However, despite this powerful tool, many organizations opt to use higher-level tools like Helm for managing deployments, as they provide a more convenient way to manage applications.
The post Kubernetes Cheat Sheet for Data Science Teams appeared first on Datafloq.
