Data is a valuable business asset, lying at the center of decision-making, customer satisfaction, and product development. However, data remains useless before it’s processed. The first step in processing involves extracting and transferring data from where they’re generated to storage locations/staging areas like data lakes or warehouses for use through data ingestion. Data ingestion is similar to an ETL or ELT process.
With the Extract, Transform, Load (ETL) process, data transformation occurs after extraction, before loading the data into storage locations. A new form of ETL called the Extract, Load, Transform (ELT) first loads the data into data lakes/warehouses before the transformation. ELT usually involves unstructured data, making the data lake the most common destination for ELT processes.
Data lakes are highly-scalable, flexible, cost-effective storage solutions that store data in raw formats. They have become a popular economical storage solution, with a projected market value of 17.60 billion by 2026, from 3.74 billion in 2020. Data ingestion into data lakes helps to create a robust data repository that can transform and adapt data for various use cases like machine learning and advanced analytics.
This article discusses data lake ingestion, its methods, architecture, and best practices.
Data Lake Ingestion Reference Architecture
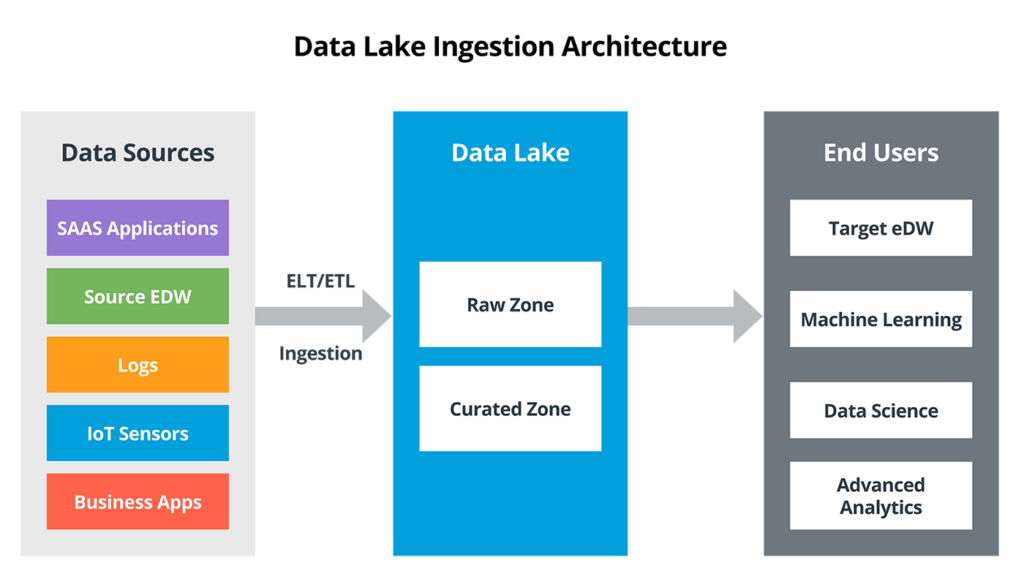
The Double-Edged Sword of Data Lake Ingestion
Data ingestion occurs in two main ways: streaming or in batches. Streaming ingestion occurs in near real-time as data generation and is ELTed into data lakes. Streaming data ingestion enables real-time events analytics and reduces the risk of losing events in case of a network crash. However, streaming ingestion can be expensive and lead to excessive traffic.
With batched ingestion, data is grouped into a server for some time before ingestion into data lakes or warehouses. This type of ingestion is cheaper and makes it easier to batch data from multiple sources in different formats before ingestion.
Because data lakes store raw, unprocessed data, enforce no schema on data loading, and are a cost-effective storage option, they remain the routine destination for data ingestion. Data lakes can also store all data types, from unstructured to structured data formats, promoting easy cloud data lake integration for diverse use cases. However, even with the benefits of flexibility, scalability, and adaptability to power data science and machine learning promised by data lakes, your data lake can become a data swamp without the proper data management architecture, tools, and data governance policies.
Here are some signs your data lake is at risk of becoming a data swamp:
- Lack of metadata management: Metadata explains valuable relationships between data and helps users, data experts, and automation tools find, use, operate, and reuse data to maximize its value. Without proper metadata management for your data lakes, there is no context to data, and data governance and quality become tough to achieve, making it unsuitable for use.
- Poor data governance: Data governance helps keep track of data ingested into data lakes and ensures data maintenance and quality during ingestion. Without defining data governance policies and quality standards, data governance efforts become hard to track, causing useless and irrelevant data to be present in your data lake.
- Presence of irrelevant and outdated data: Data lakes contain organized, flexible, and relevant data. Data swamps, on the other hand, contain old and irrelevant data without proper organization. Proper transparency into data before ingestion helps establish data relevance to businesses, thereby preventing the accumulation of unnecessary data. Without frequent audits to check data for relevance and accuracy in your data lake, your data lake can quickly become home to irrelevant, unclean data that poses no value to business decisions and negatively affects business decisions downstream.
- Lack of automation: Data lakes hold large amounts of data in multiple raw formats and keep ingesting from data sources. Without automation tools to help monitor and keep track of the data in your data lakes, maintaining organization, data management, and governance becomes tough, which may create a data swamp.
Overview: Ingestion Methods for Data Lakes
Ingestion may occur in real-time, in batches, or a combination of both.
-
- Change Data Capture (CDC) takes in data from its source layer as data changes occur. Most real-time ingestion tools use Change Data Capture (CDC) to help transfer and process only data that has changed since the last ingestion. Employing CDC for real-time ingestion helps conserve resources and reduces database workload. Real-time ingestion is crucial for businesses like financial markets, IoT devices, and preventive maintenance, whereby real-time insights are vital for decision-making.
- Batched ingestion occurs when data collection and transfer occur at regular intervals in batches on a schedule or trigger. This method is advantageous for repeated ingestions where insights have no real-time window.
- Streaming ingestion is the continuous flow of information from disparate sources to a destination for real-time processing and analytics. Real-time data streaming is beneficial when new data is generated continually.
However, before embarking on a data ingestion process and deciding on an ingestion method, one needs to create a data ingestion strategy to inform the ingestion framework. A data ingestion framework involves the tools, technologies, and processes required to ingest and load data. A data ingestion framework helps inform engineers on the tools for the ingestion process and depends on factors like:
- Data sources: What are the data sources? Are they on-premises or in the cloud? Is the source data layer comprised of information systems, text files, or streaming data?
- Size of datasets: For streaming ingestion involving larger datasets, full ingestion means more resource consumption which is more expensive. One can utilize Change Data Capture (CDC), which only captures altered records from the data source layer. CDC is ideal for streaming data, where data is continuously generated and ingested.
- Business need: Is there a time window to act on the data or not? For instance, financial applications like stock trading require real-time data streaming and processing, so real-time ingestion is crucial.
- Data location: What is the destination for your ingested data? Is it a cloud data lake or a data warehouse? For example, while Salesforce ingestion into a cloud data lake like AWS S3 proceeds fine, as S3 can house all data types, sending unstructured data to a data warehouse may result in an error if the data doesn’t match the defined schema set by the data warehouse.
Best Practices for Your Data Lake Ingestion
An efficient data ingestion process helps companies consolidate their data into one platform and powers modern-day analytics, machine learning, and other use cases. Here are some best practices to follow to build a scalable and high-performing data lake:
Transparency in Data Lake Ingestion
Knowledge of the data being streamed into your data lake, as regards schema, helps inform your data processes downstream because blind data ingestion without a strategy for your data results in bloated data lakes with little to no relevance for business. Hence, before embarking on ingestion, ensure the proper definition of the data, its purpose, proposed tools, and how ingestion tools will work with the data. Careful planning and transparency with the data help organizations choose and design an ingestion framework that creates empowering scalable data lakes.
Compress With Care
Data ingestion may involve terabytes to petabytes of data, translating to more time for ingestion and more expensive storage costs, even for cheap cloud storage options. Compression reduces storage consumption and storage costs and increases the transfer speed for ingestion jobs. However, compression shouldn’t be too heavy, as heavy compression adds complexity to your datasets, meaning more CPU costs on querying the data. One should use weaker compression that helps reduce storage without increasing CPU costs.
Master Your Data Lake
Most cloud data lakes contain extensive documentation on connecting and ingesting data into their data lakes via connectors, plugins, or managed pipelines. Before starting your ingestion, engineers need to review the documentation to build masterful ingestion pipelines. Organizations can also benefit from platforms like StreamSets, which enables easy data ingestion for streaming, batch, CDC, ETL, and ELT ingestions from any source to the destination.
Partition Your Data for Ingestion
For data ingestion jobs involving large datasets, a single running ingestion job may cause low performance and exceed the ingestion timeline, which may affect business operations and other downstream processes. However, a way to improve performance is to employ partitioning. Partitioning helps split a single large dataset ingestion job into multiple jobs running in parallel simultaneously. This practice helps to shorten ingestion times and is more efficient. Partitioning your ingestion job may involve splitting data according to similar fields or dates. However, it is essential to note the cardinal level when partitioning fields, as fields with high cardinal/unique fields could mean thousands to millions of partitioning tasks, which isn’t efficient. Low cardinal fields with reduced unique values are a better option for partitioning your dataset.
Use Automation
Keeping up with the thousands of data sources, ingestion layers, and multiple data types involved in cloud data lake ingestion is difficult without automation. With automation, data ingestion leaves little room for errors or data losses, is more reliable, faster, and efficient, and frees up time for your engineers.
Set Up Alerts at Your Data Sources
Your data source layer represents the first touchpoint for the ingestion process, and any error from there will affect other downstream processes. Therefore, setting up alerts throughout your ingestion workflow helps to catch these errors. These alerts may check for data quality to ensure you get immediate notifications for any inaccurate or invalid for immediate rectification. They can also alert for data availability and data security problems so you can fix them early.
Simplifying Data Lake Ingestion With StreamSets
Data ingestion is crucial to businesses today to get data from multiple sources to the point of storage/analysis. One cost-effective, scalable, and reliable central storage solution to house data in its raw formats is the data lake. Data lakes are very flexible, but monitoring the data lake ingestion process helps prevent them from turning into data swamps.
StreamSets enables easy cloud data lake ingestion and integration by:
- Offering multiple connectors to connect to data sources and build data ingestion pipelines using a simple, no-code interface.
- Employing resilient pipelines with built-in data drift detection to ensure continuous data flow with clean and accurate data.
- Enabling easy migration across multiple cloud providers and supporting multi-cloud and hybrid data architectures.
- Supporting pipeline automation with Python SDK.
- Allowing reusability and collaboration with pipeline fragments and pipeline templates.

The post Mastering Data Lake Ingestion: Methods and Best Practices To Know appeared first on StreamSets.
