I like to think of data quality management within the context of physical fitness.
You can get in shape with hard work, but staying in shape requires good habits. And above all else it’s a mindset and a lifestyle.
You also have to sweat. At least a little bit. No technology, including data observability, can act as a slimming belt toning your data quality while you lay back and relax.
There is also a lot of bad data fitness advice. Instead of 7 minute abs, it’s the 6 dimensions of data quality. Yes: completeness, consistency, accuracy, validity, integrity, and uniqueness all matter, but as our colleague Shane Murray points out, these are all contextual diagnostic snapshots. And they have never been mentioned in a boardroom.
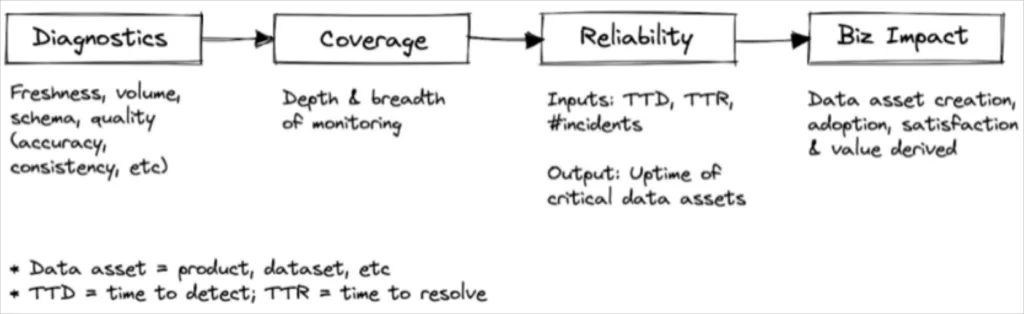
Metrics that can help a data quality management program.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine-the data pipelines, systems, and engineers-just as much as the final (data) product it spits out.
Most of all, there needs to be a repeatable process for data quality management beyond static data cleansing, testing and profiling. These legacy approaches just can’t scale within organizations that today have dozens of data sources, hundreds of data models, thousands of tables, and millions of dollars impacted by operational use cases beyond analytical dashboards.
Over the last three years, we have been personal trainers to hundreds of organizations operationalizing data quality. The most successful have iterated and progressed through the six stages captured below.
Stage 1: Baseline Current Data Reliability State
One of the best places to start a data quality management strategy is with an inventory of your current (and ideally near future) data use cases. Categorize them by:
- Analytical: Data is used primarily for decision making or evaluating the effectiveness of different business tactics via a BI dashboard. This has been the most traditional use of data within an organization and is still one of the most prominent use cases today. While you can choose to get more detailed, sometimes quick broad strokes are best for a baseline. To determine if each analytical use case is a “nice to have” or a “must have,” roughly assess the number of data consumers and the business value of the operations it is helping to optimize.
- Operational: Data used directly in support of business operations in near-real time. This is typically steaming or microbatched data. Some use cases here could be accommodating customers as part of a support/service motion or an ecommerce machine learning algorithm that recommends, “other products you might like.”
- Customer facing: Data that is surfaced within and adds value to the product offering or data that IS the product. This could be a reporting suite within a digital advertising platform for example.
Why is this important? As previously mentioned, data quality is contextual. There will be some scenarios, such as financial reporting, where accuracy is paramount. Other use cases, such as some machine learning applications, freshness will be key and “directionally accurate” will suffice.
The next step is to assess the overall performance of your systems and team. At this stage you have just begun your journey so it’s unlikely you have detailed insights into your overall data health or operations. There are some quantitative and qualitative proxies you can use however.
- Quantitative: You can’t measure the number of data incidents you aren’t catching, but can also roughly estimate your number of data incidents a year by taking the number of tables in your environment and dividing by 15. You can measure the number of data consumer complaints, overall data adoption, and levels of data trust (NPS survey). You can also ask the team to estimate the amount of time they spend on data quality management related tasks like maintaining data tests and resolving incidents.
- Qualitative: Is there a desire or an opportunity for more advanced data use cases? Do leaders feel like they’ve unlocked the full value of the organization’s data? Is the culture data driven? Was there a recent data quality disaster that led to very senior escalation?
Categorizing your data use cases and baselining current performance will also help you assess the gap between your current and desired future state across your infrastructure, team, processes, and performance. It’s an answer to broader tactical questions that impact data quality across:
- People:
- Should there be a central data team, decentralized data mesh, or a hybrid with a data center of excellence?
- Do I need specialized roles and/or teams to manage data governance such as data stewards or data quality such as data reliability engineers?
- Process:
- Are we efficient at identifying the root cause of data incidents?
- Do we understand the relative importance of each asset and how they are related?
- What data SLAs should we have in place?
- How do we onboard data sets?
- What level of documentation is appropriate?
- How do we enable discovery and prioritize self-service access to data?
“Given that we are in the financial sector, we see quite disparate use-cases for both analytical and operational reporting which require high-levels of accuracy” says Checkout.com Senior Data Engineer Martynas Matimaitis. “That forced our hands to [scale data quality management] quite early on in our journey, and that became a crucial part of our day-to-day business.”
Stage 2: Organizational Alignment
Once you have a baseline and an informed opinion, you are ready to start building support for your initiative. You will want to start by understanding what pain is felt by different stakeholders.
This will help you rightsize your initiative and align the goals to business value. I’d recommend considering data downtime as a key data quality metric, but ultimately the best metric is the one that measures what your boss and customers care about.
If there is no pain, you need to take a moment to understand why. It could be the scale of your data operations or the overall importance of your data isn’t mature enough to warrant an investment in improving data quality. However, assuming you have more than 50 tables and a few members on your data team that is unlikely to be the case.
What’s more likely is your organization has quite a bit of unrealized risk. The data quality is low and a costly data incident is just around the corner…but it hasn’t struck yet. Your data consumers will generally trust the data until you give them a reason not to. At that point, trust is much harder to regain than it was to lose.
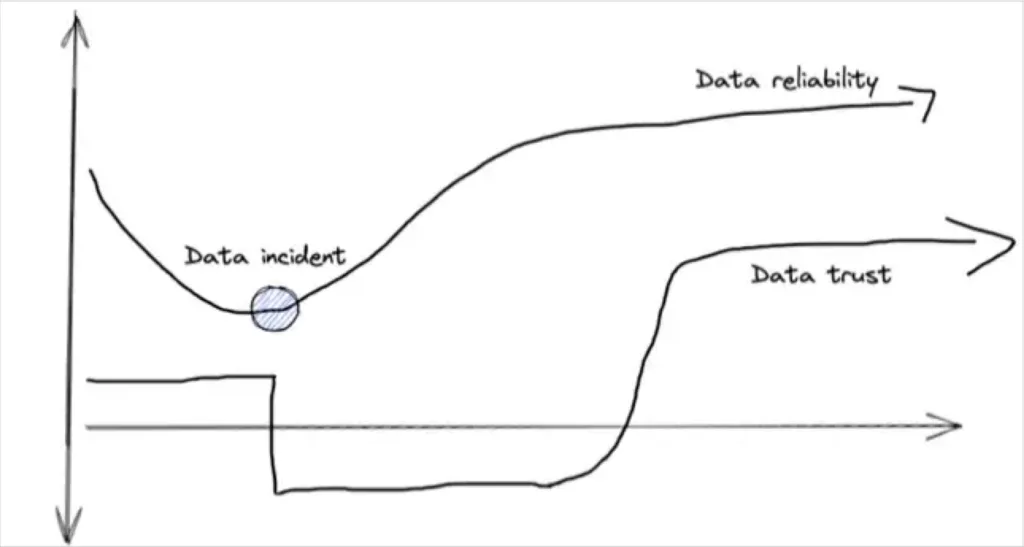
Data trust is often a lagging indicator of data reliability levels.
The overall risk of poor data quality can be difficult to assess. The consequences of bad data can range from slightly under optimized decision making to reporting incorrect data to Wall Street. One approach is to pool this risk by estimating your data downtime and attributing an inefficiency cost to it. Or you could take established industry baselines- our study shows bad data can impact on average 26% of a company’s revenue.
That risk assessment and cost of business stakeholders dealing with bad data will be informative if a bit fuzzy. It should also be paired with the cost to the data team of dealing with bad data. This can be done by totaling up the amount of time spent on data quality related tasks, wincing, and then multiplying that time by the average data engineering salary.
Pro-Tip: Data testing is often one of the data team’s biggest inefficiencies. It is time consuming to define, maintain, and scale every expectation and assumption across every dataset. Worse, because data can break in near infinite number of ways (unknown unknown) this level of coverage is often woefully inadequate.
Congratulations! You now have a business case for your data quality management initiative and the changes you need to make across your people, technology, and processes.
At this point, the following stages will assume you have obtained a mandate and made a decision to either build or acquire a data quality or data observability solution to assist in your efforts. Now, it’s time to implement and scale.
Stage 3: Broad Data Quality Coverage and Full Visibility
The third data quality management stage is to make sure you have basic machine learning monitors (freshness, volume, schema) in place across your data environment. For many organizations (excluding the largest enterprises), you will want to roll this out across every data product, domain, and department rather than pilot and scale.
This will accelerate your time to value and help you establish critical touch points with different teams if you haven’t done so already.
Another reason for a wide roll out is that, even with the most decentralized organizations, data is interdependent. If you install fire depressant systems in the living room while you have a fire in the kitchen, it doesn’t do you much good.
Also, wide-scale data monitoring and/or data observability will give you a complete picture of your data environment and the overall health. Having the 30,000 foot view is helpful as you enter the next stage of data quality management.
“With…broad coverage and automated lineage…our team can identify, understand downstream impacts, prioritize, and resolve data issues at a much faster rate,” said Ashley VanName, general manager of data engineering, JetBlue.
Stage 4: Incident Triage and Resolution
At this data quality management stage, we want to start optimizing our incident triage and resolution response. This involves setting up clear lines of ownership. There should be team owners for data quality as well as overall data asset owners at the data product and even data pipeline level. Breaking your environment into domains, if you haven’t already, can help create additional accountability and transparency for the overall data health levels maintained by different groups.
Having clear ownership also enables fine tuning your alert settings, making sure they are sent to the right communication channels of the responsible team at the right level of escalation.
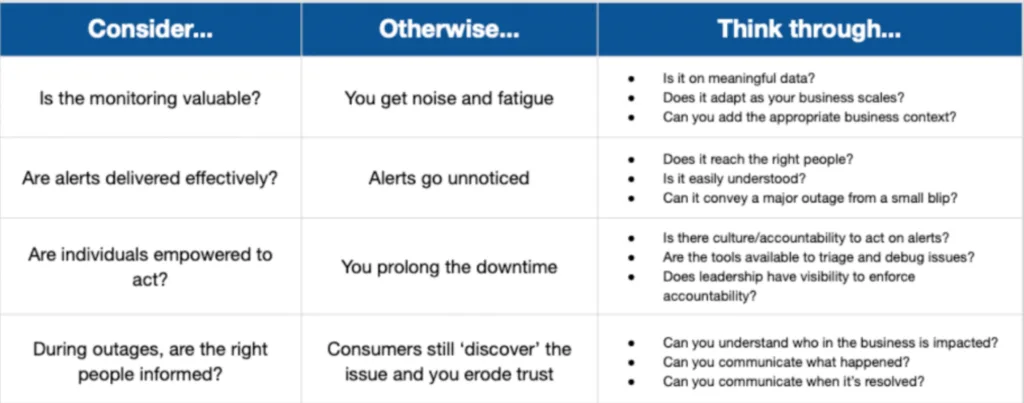
Alerting considerations for a data quality management initiative.
“We started building these relationships where I know who’s the team driving the data set,” said Lior Solomon, VP of Data at Drata. “I can set up these Slack channels where the alerts go and make sure the stakeholders are also on that channel and the publishers are on that channel and we have a whole kumbaya to understand if a problem should be investigated.”
Stage 5: Custom data quality monitors
This data quality management stage is focused on layering more sophisticated, custom monitors. These can be either manually defined-for example if data needs to be fresh at 8:00 am every weekday for a meticulous executive-or machine learning based. In the latter case, you indicate which tables or segments of the data are important to examine and the ML alerts trigger when the data starts to look awry.
We recommend layering on custom monitors on your organization’s most critical data assets. These can typically be identified as those that have many downstream consumers or important dependencies.
Custom monitors and SLAs can also be built around different data reliability tiers to help set expectations. You can certify the most reliable datasets “gold” or label an ad-hoc data pull for a limited use case as “bronze” to indicate it is not supported as robustly.
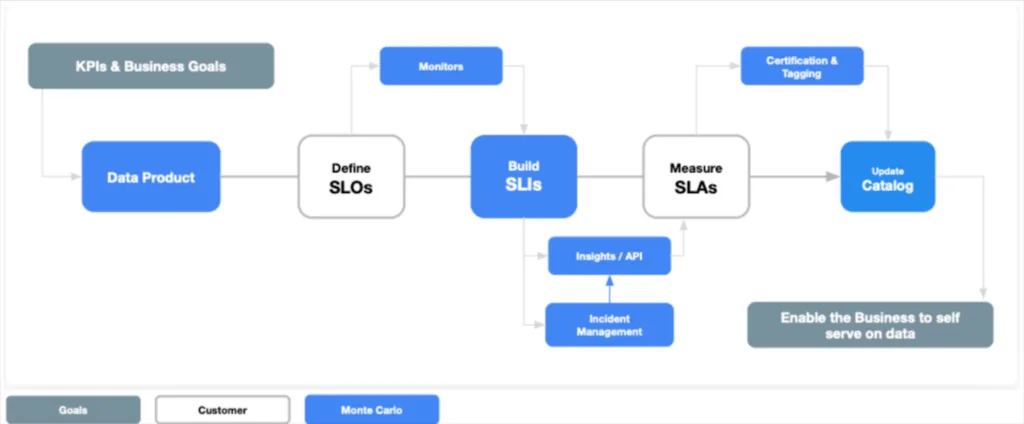
Data certification as part of a data quality management program.
The most sophisticated organizations manage a large portion of their custom data quality monitors through code (monitors as code) as part of the CI/CD process.
The Checkout.com data team reduced its reliance on manual monitors and tests by adding monitors as code functionality into every deployment pipeline. This enabled them to deploy monitors within their dbt repository, which helped harmonize and scale the data platform.
“Monitoring logic is now part of the same depository and is stacked in the same place as a data pipeline, and it becomes an integral part of every single deployment,” says Martynas. In addition, that centralized monitoring logic enables the clear and easy display of all monitors and issues, which expedites time to resolution.
Stage 6: Incident Prevention
At this point, we have driven significant value to the business and noticeably improved data quality management at our organization. The previous data quality management stages have helped dramatically reduce our time-to-detection and time-to-resolution, but there is a third variable in the data downtime formula: number of data incidents.
One of the main goals of this data quality management stage is to start shifting data quality left and operationalizing your preventive maintenance. In other words, preventing data incidents before a pipeline breaks.
That can be done by focusing on data health insights like unused tables or deteriorating queries. Analyzing and reporting the data quality levels or SLA adherence across domains can also help data leaders determine where to allocate resources.
“Data lineage highlights upstream and downstream dependencies in our data ecosystem, including Salesforce, to give us a better understanding of our data health,” said Yoav Kamin, business analysis group leader at Moon Active. “Instead of being reactive and fixing the dashboard after it breaks, [our data quality management program] provides the visibility that we need to be proactive.”
Final thoughts
We covered a lot of ground in this article – some might call it a data reliability marathon. Some of our key data quality management takeaways include:
- Make sure you are monitoring both the data pipeline and the data flowing through it.
- You can build a business case for data monitoring by understanding the amount of time your team spends fixing pipelines and the impact it has on the business.
- You can build or buy data monitoring-the choice is yours-but if you decide to buy a solution be sure to evaluate its end-to-end visibility, monitoring scope, and incident resolution capabilities.
- Operationalize data monitoring by starting with broad coverage and mature your alerting, ownership, preventive maintenance, and programmatic operations over time.
Perhaps the most important point is that data pipelines will break and data will “go bad” – unless you’re keeping them healthy.
Whatever your next data quality management step entails, it’s important to take it sooner rather than later. You’ll thank us later.
The post Data Quality Management: 6 Stages For Scaling Data Reliability appeared first on Datafloq.

{kind=link}