Newcomers to StreamSets might not know that we have four engines under the Control Hub hood: Data Collector, Transformer for Spark, Transformer for Snowflake, and Mainframe Collector. This fact is easy to miss, because of how streamlined the experience is for users. The canvas, toolbars, and experience are largely the same for each engine by design. The intent is to minimize the shock users can experience when tools change interfaces with every new product. The simple drop downs and a uniform visual experience across each engine make it much easier to select the right engine for the right job based on the use case rather than basing your decision on what interface is easier or more familiar.
Today I’ll be talking about Transformer for Spark.
What Is Transformer for Spark?
Transformer for Spark is the engine dedicated to the heavy lifting of data transformation. You’ll want to choose this engine when you have a variety of data sources and need to make a lot of changes. It gives you the power of Apache Spark without the need to learn to code, plus the flexibility to choose your platform for execution — Databricks, EMR, Google Dataproc or another Spark platform.
Now that we’ve explored the context, let’s talk about tips and tricks for actually creating a data pipeline with Transformer for Spark. One cool feature of Transformer for Spark is its JDBC multitable consumer. The origins for connecting to MySQL, Oracle, Postgres and SQL Server all allow you to read from multiple tables. This means you don’t have to create multiple pipelines or multiple streams of data within a single pipeline in order to collect data from a variety of tables within a database.
Why Is JDBC Multitable Consumer Cool?
What’s wrong with creating multiple pipelines or multiple streams? Absolutely nothing, technically. While it is definitely possible to create multiple instances easily with StreamSets duplicate and fragment features, a tighter pipeline configuration with fewer elements is always preferable. Simpler really is better.
Take a look at the screenshot below to see how multiple streams of data within a single pipeline can complicate the view in the pipeline canvas. You’ll see two data streams from a local directory blended together for reporting. For some origins, like the local directory origin shown here, JDBC multitable consumer you can do more with less.
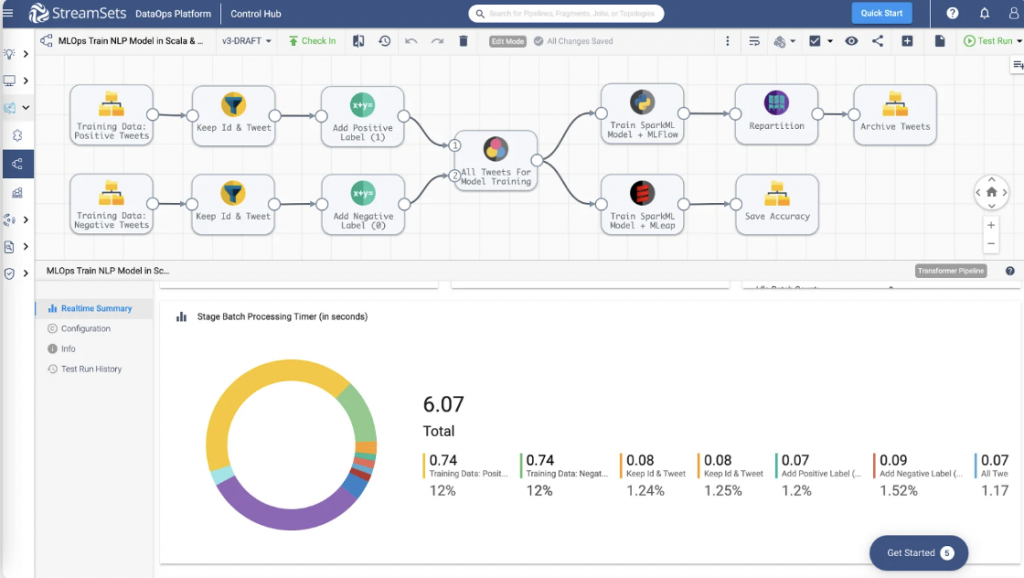
How To Use It
Let’s take a look at how JDBC multitable consumer works in practice using the Oracle JDBC origin. You can see by looking at the configuration window for the origin (screenshot below) how easy it is to add Tables to this origin. Our examples, multitable_a and multitable_b, can be added individually or, if you have a lot of them, in bulk edit mode.
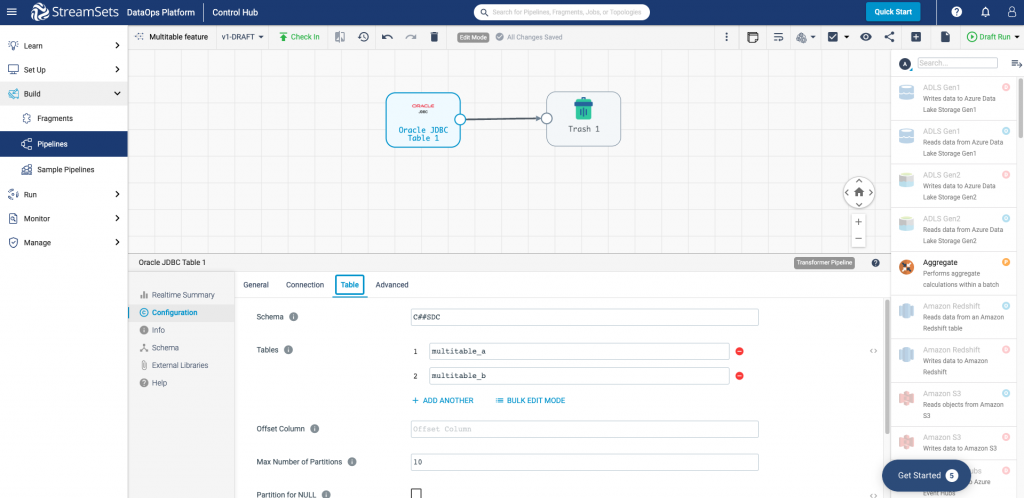
You don’t have to guess where the data in your destination came from because pipelines using the JDBC multitable consumer origin generates batch headers for each batch and writes the jdbc.table attribute in the header. In other words, the attribute stores the name of the table that the origin reads for the batch.
Keep up to date on other tips and tricks using Transformer for Spark and other supported engines by joining us in the StreamSets Community.

The post Transformer for Spark: Multitable Consumer appeared first on StreamSets.
