Data warehouses and data lakes are the most common central data repositories employed by most data-driven organizations today, each with its own strengths and tradeoffs. For one, while data warehouses allow businesses to organize historical datasets for use in business intelligence (BI) and analytics, they quickly become more cost-intensive as datasets grow because of the combined use of compute and storage resources. Additionally, data warehouses can’t handle the varied nature of data (structured, unstructured, and semi-structured) seen today.
Data lakes answered this problem with their low-cost of storage and ability to handle data in various formats. Furthermore, their ability to manage data in multiple formats makes data lake architecture applicable to different use cases like analytics and machine learning systems. That said, data lakes have limitations, too; their storage of data as files without a defined schema makes it challenging to perform critical data management to enable ETL transactions and leads to the creation of orphaned data. This is where the need for lakehouses like Delta Lake arose.
Let’s delve into how Delta lake works and what its architecture looks like.
What Is Delta Lake?
Delta Lake is an open-source storage layer built atop a data lake that confers reliability and ACID (Atomicity, Consistency, Isolation, and Durability) transactions. It enables a continuous and simplified data architecture for organizations. A data lake stores data in Parquet formats and enables a lakehouse data architecture, which helps organizations achieve a single, continuous data system that combines the best features of both the data warehouse and data lake while supporting streaming and batch processing.
How Delta Lake Works and Why It Matters
A Delta Lake enables the building of a data lakehouse. Common lakehouses include the Databricks Lakehouse and Azure Databricks. This continuous data architecture allows organizations to harness the benefits of data warehouses and data lakes with reduced management complexity and cost. Here are some ways Delta Lake improves the use of data warehouses and lakes:
- Enables a lakehouse architecture: Delta Lake enables a continuous and simplified data architecture that allows organizations to handle and process massive volumes of streaming and batch data without the management and operational hassles involved in managing streaming, data warehouses, and data lakes separately.
- Enables intelligent data management for data lakes: Delta Lake offers efficient and scalable metadata handling, which provides information about the massive data volumes in data lakes. With this information, data governance and management tasks proceed more efficiently.
- Schema enforcement for improved data quality: Because data lakes lack a defined schema, it becomes easy for bad/incompatible data to enter data systems. There is improved data quality thanks to automatic schema validation, which validates DataFrame and table compatibility before writes.
- Enables ACID transactions: Most organizational data architectures involve a lot of ETL and ELT movement in and out of data storage, which opens it up to more complexity and failure at node entry points. Delta Lake ensures the durability and persistence of data during ETL and other data operations. Delta lake captures all changes made to data during data operations in a transaction log, thereby ensuring data integrity and reliability during data operations.
Delta Lake Architecture Diagram
Delta Lake is an improvement from the lambda architecture whereby streaming and batch processing occur parallel, and results merge to provide a query response. However, this method means more complexity and difficulty maintaining and operating both the streaming and batch processes. Unlike the lambda architecture, Delta Lake is a continuous data architecture that combines streaming and batch workflows in a shared file store through a connected pipeline.
The stored data file has three layers, with the data getting more refined as it progresses downstream in the dataflow;
- Bronze tables: This table contains the raw data ingested from multiple sources like the Internet of Things (IoT) systems, CRM, RDBMS, and JSON files.
- Silver tables: This layer contains a more refined view of our data after undergoing transformation and feature engineering processes.
- Gold tables: This final layer is often made available for end users in BI reporting and analysis or use in machine learning processes.
The three layers are referred to as a multi-hop architecture.
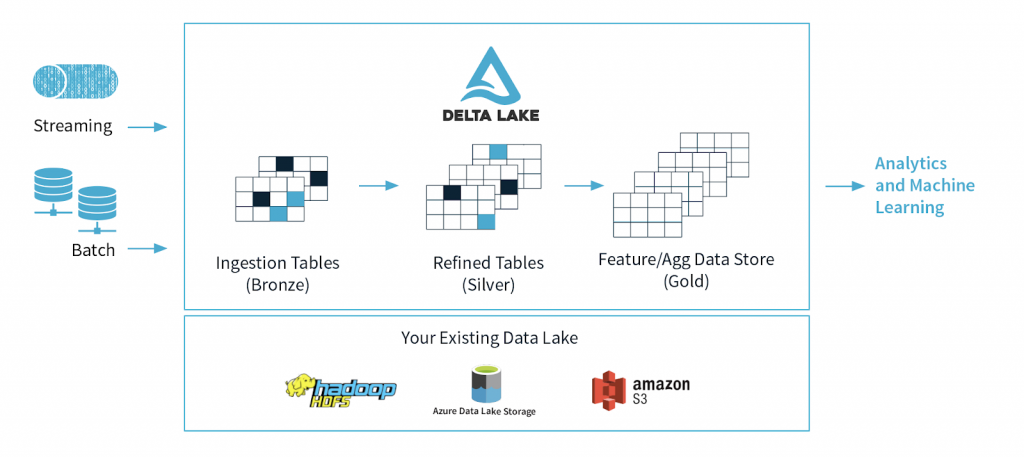
Image courtesy of DataBricks
Key Benefits and Features of Delta Lake
- Audit trails and history: In Delta Lake, every write exists as a transaction and is serially recorded in a transaction log. Therefore, any changes or commits made to the transaction log are recorded, leaving a complete trail for use in historical audits, versioning, or for time traveling purposes. This Delta Lake feature helps ensure data integrity and reliability for business data operations.
- Time traveling and data versioning: Because each write creates a new version and stores the older version in the transaction log, users can view/revert to older data versions by providing the timestamp or version number of an existing table or directory to the Sparks read API. Using the version number provided, the Delta Lake then constructs a full snapshot of the version with the information provided by the transaction log. Rollbacks and versioning play a vital role in machine learning experimentation, whereby data scientists iteratively change hyperparameters to train models and can revert to changes if needed.
- Unifies batch and stream processing: Every table in a Delta Lake is a batch and streaming sink. With Sparks structured streaming, organizations can efficiently stream and process streaming data. Additionally, with the efficient metadata handling, ease of scale, and ACID quality of each transaction, near-real-time analytics become possible without utilizing a more complicated two-tiered data architecture.
- Efficient and scalable metadata handling: Delta Lakes store metadata information in the transaction log and leverages Spark’s distributed processing power to quickly process and efficiently read and handle large volumes of data metadata, thus improving data governance.
- ACID transactions: Delta Lakes ensure that users always see a consistent data view in a table or directory. It guarantees this by capturing every change made in a transaction log and isolating it at the strongest isolation level, the serializable level. In the serializable level, every existing operation has and follows a serial sequence that, when executed one by one, provides the same result as seen in the table.
- Data Manipulation Language (DML) operations: Delta Lakes supports DML operations like updates, deletes, and merges, which play a role in complex data operations like change-data-capture (CDC), streaming upserts, and slowly-changing-dimension (SCD). Operations like CDC ensure data synchronization in all data systems and minimizes the time and resources spent on ELT operations. For instance, using the CDC, instead of ETL-ing all the available data, only the recently updated data since the last operation undergoes a transformation.
- Schema enforcement: Delta Lakes perform automatic schema validation by checking against a set of rules to determine the compatibility of a write from a DataFrame to a table. One such rule is the existence of all DataFrame columns in the target table. An occurrence of an extra or missing column in the DataFrame raises an exception error. Another rule is that the DataFrame and target table must contain the same column types, which otherwise will raise an exception. Delta Lake also use DDL (Data Definition Language) to add new columns explicitly. This data lake feature helps prevent the ingestion of incorrect data, thereby ensuring high data quality.
- Compatibility with Sparks API: Delta lake is built on Apache Spark and is fully compatible with Spark API, which helps build efficient and reliable big data pipelines.
- Flexibility and integration: Delta lake is an open-source storage layer and utilizes the Parquet format to store data files, which promotes data sharing and makes it easier to integrate with other technologies and drive innovation.
Delta Lake and StreamSets
StreamSets is a DataOps platform that enables organizations to perform data operations on Delta Lake files without the additional cost of having to configure a Delta Lake cluster. By using one of the integration tools available in the Streamsets Data Collector Engine (SDC), data engineers and data scientists can build pipelines that stream data into a Delta Lake for use in analytics and machine learning. StreamSets also enables CDC, which helps read changes from a source, replicates and loads the changed data in your Delta Lake table using the merge command. Organizations looking for more power can also perform data ingestions and transformations on the incoming data using the StreamSets Transformer Engine.
Request a demo with today to learn more about building your pipelines.

The post Delta Lake Architecture: A Bridge Between Data Lakes & Data Warehouses appeared first on StreamSets.
