The best way to understand something is through concrete examples. I’ve put together seven examples of data pipelines that represent very typical patterns that we see our customers engage in. These are also patterns that are frequently encountered by data engineers in the production environments of any tool.
Use these patterns as a starting point for your own data integration project, or recreate them for practice in real-world data pipelines.
1. Change Data Capture Pipeline
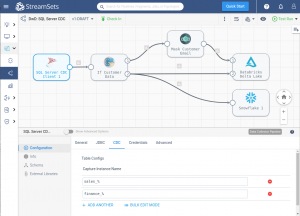
This is a streaming Change Data Capture (CDC) pipeline that captures any changes to the data at the source and sends it along to the destination. In this case, the source is a SQL server database, and the destination is two cloud warehouses: Databricks and Snowflake.
2. Migration Pipeline From an On-Premise Database to a Cloud Warehouse
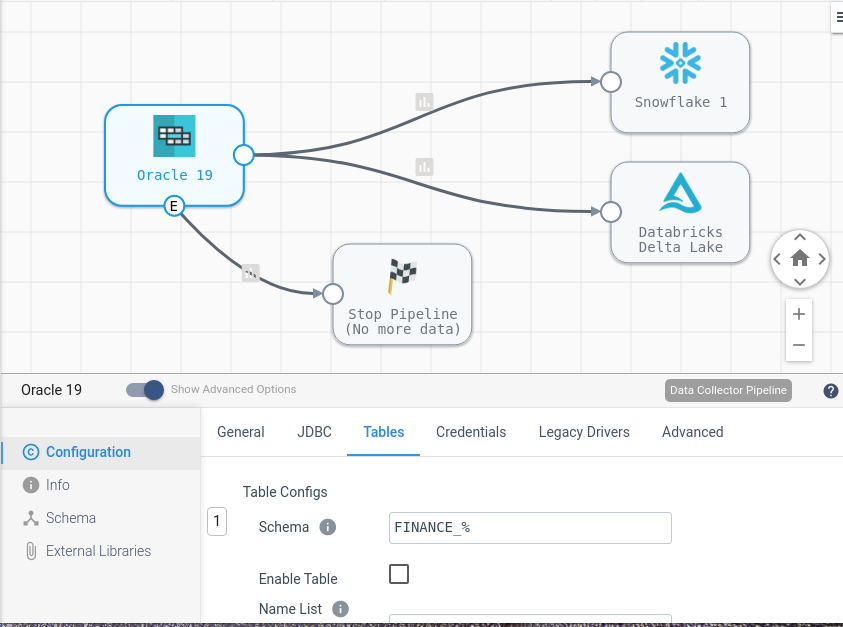
In this pipeline, we see a migration pipeline from an on-prem oracle database to both Snowflake and Databricks. This is a pattern a lot of StreamSets customers use when migrating from traditional databases to cloud data warehouses. Note that the inclusion of the pipeline finisher stage (the black and white checkered flag) means that this pipeline is a batch pipeline that will stop after a condition is met instead of running endlessly. In this pipeline, the condition to be met is “No more data” meaning the pipeline will stop when there is no more data being received from the source.
3. Streaming Pipeline from Kafka to Elasticsearch on AWS

We return to streaming pipelines with this example that uses Kafka as the source, performs several transforms to the data, and then sends the data to an Elasticsearch destination running on AWS. This pattern is used frequently for log or event processing, as both Kafka and Elasticsearch play very well together.
4. Reverse ETL Pipeline Example
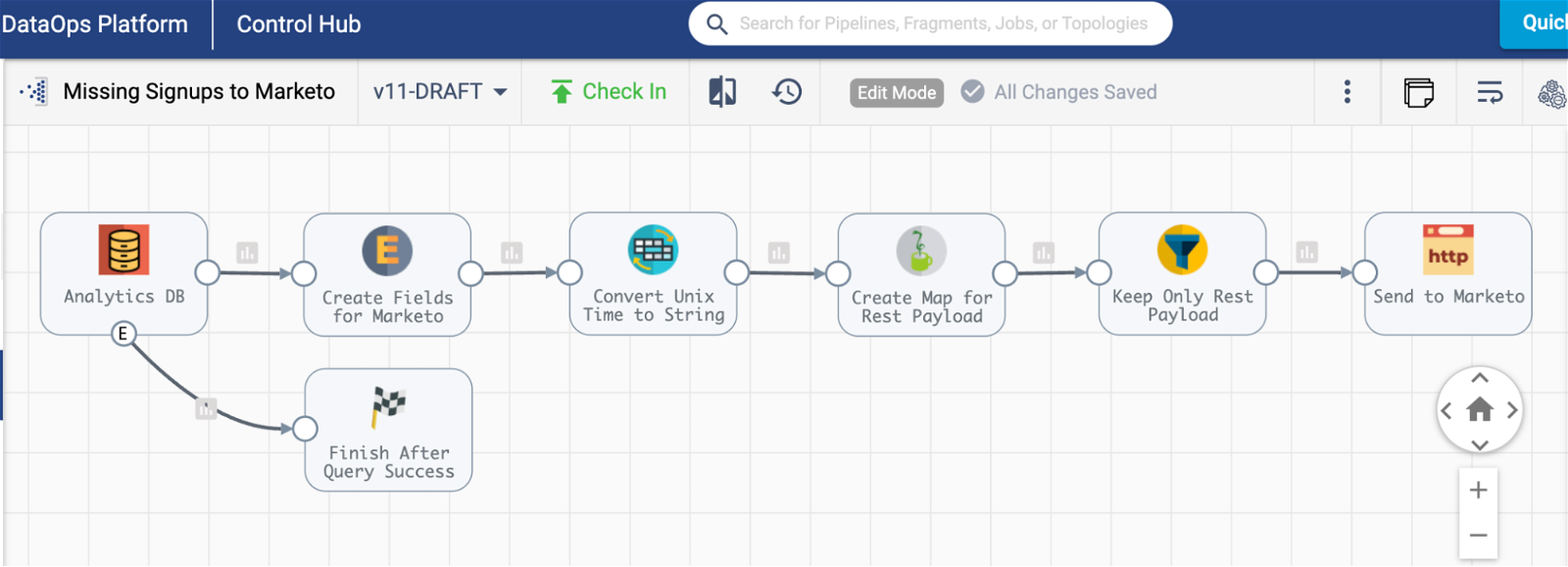
A reverse ETL pipeline is one in which data is passed back into a tool from a data warehouse. In a traditional ETL pipeline (not reverse ETL) the pattern goes the opposite way, with all the data being pulled from various sources across an enterprise into the data warehouses. In this reverse ETL example, we have a pipeline connecting to a MySQL database as a source, performing some transformations, and sending that data into Marketo. Note the presence of the pipeline finisher stage in this pipeline that makes this pipeline a batch pipeline.
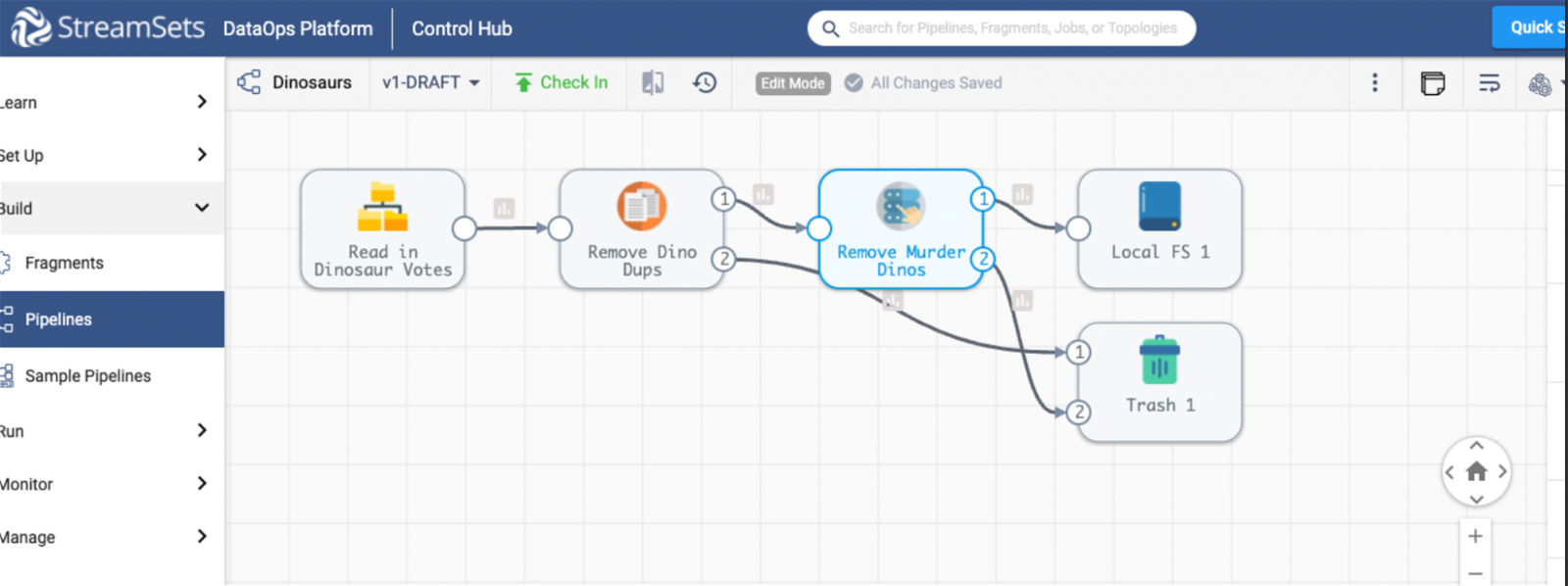
5. Pipeline Using A Fragment

In this example, we see a pipeline that uses a fragment. Fragments are bits and pieces of pipelines that are reusable. Within StreamSets, you can easily swap them in and out of pipelines depending on your need. An example might be a string of processors that transform your data in a consistent way, like adding a date of ingestion or a unique identifier. You might prefer that these transforms be done to any data flowing through a pipeline. With fragments, all you need to do is set it up once and the processes can be made available across your organization.
6. Pipeline from Local File Storage to Local File Storage
You’re probably wondering why a pattern like this exists. You might be surprised to learn that there are quite a few instances of pipelines that use a local origin and local destination. This is because StreamSets handles file storage extremely well due to being schema agnostic. Because of this, it can ingest new columns or columns in a different order across many different files without any further intervention.
Once you make your pipeline, whatever ends up in your origin will end up in your destination without you having to touch it again. Another way StreamSets handles files so well is that it is quite easy (just a drop down menu) to change file format. So, it is possible to quickly and easily save many .csvs to .json files or avro files or .txt files, etc.
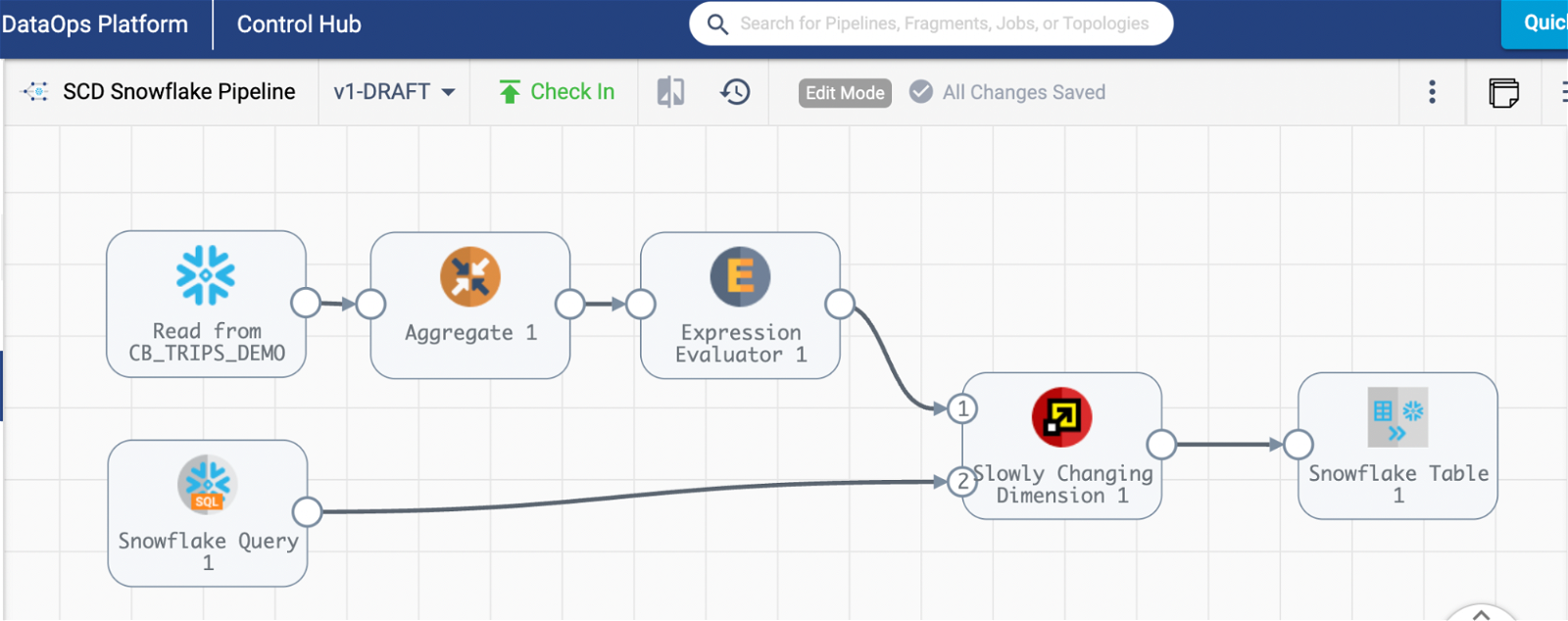
7. Slowly Changing Dimensions Pipeline
This pipeline is an example of a type 2 slowly changing dimension pipeline from Snowflake into Snowflake. In this example, we see data from a table being transformed and going into the slowly changing dimension (SCD) stage as data flow 1 and change data arriving in the SCD stage as data flow 2. Type 2 SCD adds a deactivated status and end and start date to the records being changed. This newly updated data is sent to a new table in Snowflake to serve both the active and historical record.
Straightforward Data Engineering
Whatever your pipeline pattern, StreamSets can make the process of creating pipelines as straightforward as data engineering ever is. With a drag-and-drop interface and a variety of pre-built processors at your disposal, your hardest task when creating your pipeline is developing a deep understanding of your data. Luckily, that’s the fun part. Use these pipeline examples as a jumping off point or as good practice in the principles of data engineering. As you build, please feel free to share your pipeline patterns with the StreamSets community.

The post 7 Examples of Data Pipelines appeared first on StreamSets.
